
在MCU开发和应用中,工程师都需要进行MCU的能力测试,通用的做法是用Benchmark(基准)程序来测试。然而,在做基准测试时,编译器的优化能力也在测试结果中有较为明显的影响,同一套硬件平台,选用不同的编译器和不同的优化选项,可能得出的结果相差较大。
为了最大程度释放MCU的性能,在基准测试中取得最理想的结果,往往需要工程师不仅对自身的硬件比较了解,更需要深入了解编译器的优化原理,并灵活应用,才能在基准测试中发挥出MCU的全部性能。IAR Systems作为全球知名的嵌入式工具厂商,其编译器在优化能力上有独特的优势,MCU配合IAR的编译器往往能够得出较好的基准测试结果。
本文以已在MCU领域内广泛使用的IAR Embedded Workbench开发工具套件为例,来分享MCU软件基准测试应该注意的项目和以下技巧,从而帮助读者能够去生成业内最高效和最完备的代码。利用以下项目和设置,工程师可以精准调整优化等级,最大限度地进行测试和提升所开发和应用代码的性能。
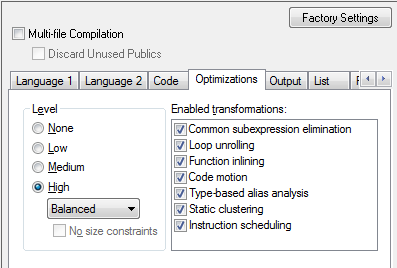
利用IAR Embedded Workbench等开发工具套件,工程师可以对整个工程范围或对单个文件设定优化级别和类型。在源代码中,甚至可以对单个函数使用 #pragma optimize 指令来完成此操作。
优化的目的是减少代码尺寸和提高执行速度。如果只能满足其中一个目标,编译器会根据用户指定的设置进行优先处理。因此,在实际的软件基准测试中,工程师可以尝试各种设置来获得最佳效果。举个例子,由于函数内联更侧重于执行速度的优化,相较于采用通用代码尺寸优化设置,采用函数内联与通用代码执行速度优化设置将获得更小的程序代码。
为了能够充分地发挥MCU器件的性能和减少应用中的问题,软件开发必须充分考虑MCU器件的内存等资源限制,因此需要为目标器件和项目选择尽可能小的内存模型。小型内存模型的优点包括:
诸如IAR Embedded Workbench这样的成熟的开发工具套件也集成了相关评估功能,可以对内存模型进行多方面评估,从而帮助工程师去测试软件的规模和优化设计。
默认情况下,运行时库是以最高代码尺寸优化级别进行编译的。如果您想要对速度进行优化,请考虑重新编译生成这些库。可以通过配置选项来设置某些标准库功能(如语言环境、文件描述符和多字节)最适合的级别。
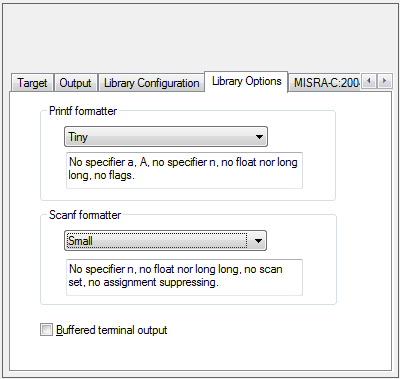
根据具体需求,在库选项中选择 scanf 输入和 printf 的格式。默认选项并非最小格式。
数据类型与代码尺寸或者执行速度息息相关,因此需要利用开发工具来对数据类型进行观察和分析,以便找到适合硬件资源的类型。在IAR Embedded Workbench开发工具套件中,开发人员可以从以下几个方面着手进行测试和优化:

检查能提高性能的目标特定选项,这在日常的MCU设计和应用开发中往往需要工程师具有相当的经验,但是通过使用诸如IAR Embedded Workbench这类成熟的开发工具套件则可以快速而完善地完成必要的性能检查:
所有的MCU开发工具都应该提供基准测试相关代码,但是成熟的通用开发工具的代码库都是这些提供商在相关领域经验的浓缩,因此更为全面和高效。其中的重要经验包括:

通过使用诸如IAR Embedded Workbench这类成熟的开发工具套件,发挥其在几十年全球性应用中行汇聚和迭代出的知识,MCU设计和应用开发工程师可以快速完成上述这些必要的性能测试,同时也可以进一步有针对性地发挥MCU的性能,从而实现目标器件最优化的、软硬件合一的功能。
 最前沿的电子设计资讯
最前沿的电子设计资讯
