
CEVA这家以色列公司在2015年市场表现相当优异,目前市值已近5亿美金,虽然距离ARM两百多亿的市值还有点距离,但其在DSP授权领域的地位不会亚于ARM在CPU领域。(CEVA现在DSP授权领域市场份额超过任何其他DSP IP供应商的三倍以上)。 “CEVA和ARM的合作关系远大于竞争关系。”CEVA市场营销副总裁Eran Briman(下图)指出。的确,两家公司的合作历史持续了数年,曾合作推出不少设计方案,且CEVA也曾增加用于ARM AXI4总线的支持等,方便双方的IP相互集成。

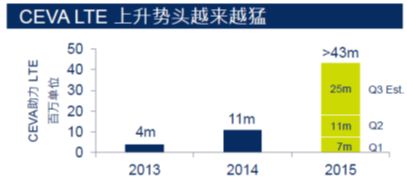
对于CEVA未来的市场增长,Briman认为主要将集中在两部分。第一部分增长集中在LTE智能手机及平板电脑。预计到2019年将会有超过65亿个使用智能手机的3G和4G用户,而目前仅有35亿个。 “尽管高通在之前两三年占据了90%的市场份额,但现在中国厂商已经赶上来了,现在联芯基于CEVA的芯片单款出货量已超千万片。”Briman指出。现在中国60%的新手机是基于LTE的。 另外,值得一提的是,CEVA的营收中有40%来自中国。 另外传言的在iPhone7中使用英特尔处理器的消息也是极大利好(英特尔并购的英飞凌移动采用的是CEVA的DPS核)
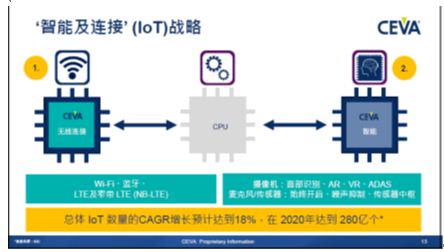
第二部分增长就是“智能与连接”设备,这方面涵盖无线连接、图像与视觉、音频/语音/感测、以及通信四大类IP。 “目前我们有超过50家的新的非基带应用客户。”Briman透露。 我们看到几家IP厂商都在针对IoT的连接和智能两方面做文章,在EDN小编看来,CEVA的第四代图像和视觉处理IP还是相当有特色的,另外该公司一年多前收购的Riviera Waves对其无线连接产品线也是极好的补充。
在被问及CEVA是否会提供设计服务时,Briman表示,CEVA会通过合作伙伴提供设计服务,但自身仍将是一家纯IP公司,集中精力做自己擅长做的部分。 而且Briman表示CEVA的产品主要是以软核方式提供(不考虑工艺节点)。不过,已有一些合作伙伴会把部分产品做成硬核,以便迎合一些设计能力欠缺的小的IC公司或系统公司的需求。 下面是一些CEVA近期推出的重点产品和大家分享。
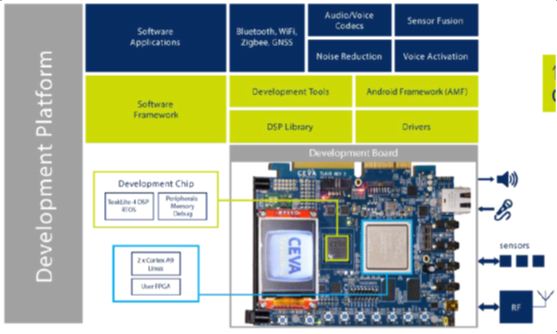
给SoC工程师准备的开发板:CEVA“智能及连接”平台
这是一个与灿芯半导体(中芯国际参与投资)合作的产物,用来帮助工程师开发低功耗的针对IoT应用的SoC。 该开发平台包括一个500MHz TeakLite-4 DSP硅器件,以及ZYNQ FPGA和2颗Cortex A9,此外还包括了多项无线连接标准(蓝牙、Wi-Fi、Zigbee和GNSS)、集成了感测IP(音频、运动)等,以及多个外设和系统接口。 Briman指出,这个平台的推出可以大大的加快SoC的验证过程,帮助工程师做到一次流片成功。

另外,通过这个平台,可以方便软件工程师在产品出来之前就开始工作,对于开发效率来说非常有帮助。
实现计算机视觉大pk:XM4与Tegra K1
在智能手机、平板电脑、汽车安全和信息娱乐、机器人、安防监控、增强现实、无人机和标识应用的推动之下,在嵌入式系统中集成高度智能视觉处理功能的趋势正在加速发展。 然而,随着嵌入式系统对小型化、低功耗化的要求增加,增加计算视觉非常具有挑战性。CEVA-XM4中采用了可编程宽矢量架构、定/浮点处理能力、多重同步标量单位,以及一个专门针对计算机视觉处理需求的低功耗指令集,使其比 CEVA-MM3101实现多达8倍的性能增强,并提升多达35%的能效。 Briman给出了与业界领先GPU用于实施计算机视觉的性能比较:
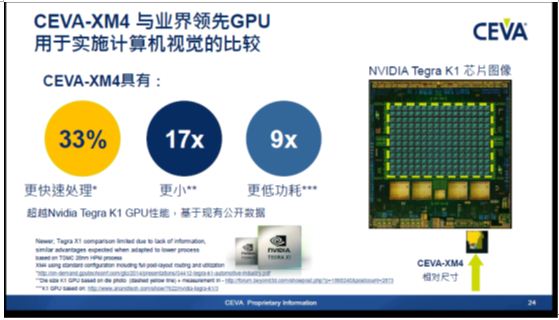
从图中可以看到,两者在处理速度,外形尺寸和功耗方面完全不是一个数量级的。 不过,Briman对此也承认,图形处理器的优势是在数据的输出方面,而XM4是更适合从摄像头到处理器的输入的数据处理。 题外话,看起来Tegra K1在手机和平板领域失宠后,想进入视觉处理领域,似乎也困难重重。
CDNN:高大上的深层神经网络
CEVA 在本月初推出的深层神经网络(CEVA Deep Neural Network, CDNN),可以简化低功耗嵌入式系统中的机器学习部署。 “通过利用CEVA-XM4 图像和视觉DSP的处理能力,CDNN使得嵌入式系统执行深层学习任务的速度比基于GPU的领先系统提高3倍,同时消耗的功率减少30倍,所需存储带宽减少15倍。”Briman表示。 “简单来说,就是效果好、算法简单,把之前在云端服务器上实现的功能嵌入式化,放于前端设备中。”他补充道。
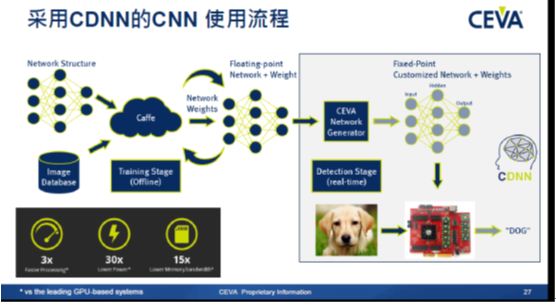
Synopsys前不久推出的EV处理器系列也实现了一种前馈卷积神经网络(CNN)结构,支持一个可编程的点对点串流互连网络,以用于快速和准确的目标监测这一视觉处理的关键任务。但Briman认为XM4用于深层学习更有优势:

该方案可以充分利用CEVA-MM3101的基础设施、工具和生态系统,已经拥有超过15个授权厂商和30 多家合作伙伴,多种潜在应用包括用于安全的行人检测和面部检测、先进驾驶辅助系统(ADAS)、以及基于低功耗相机功能系统的其它嵌入式设备。
《电子技术设计》网站版权所有,谢绝转载
 最前沿的电子设计资讯
最前沿的电子设计资讯

