
ChatGPT的“横空出世”,给科技领域再次带来一场新的革命。随后,谷歌推出Bard,百度测试文心一言,全球各巨头以及垂直细分领域的大型企业均迅速加入了这场AI的革命之中;工程师们更是跃跃欲试,或直接投入其中并为之“痴迷”,又或站在不同的“高度”审视着这场科技盛筵,内心却在寻找真正的高速入口。或许,ChatGPT引发的AI变革将成为二十多年以来的又一次科技大潮。然而,与2000年前后的互联网浪潮相比,这次基于大语言模型的生成式AI并非真的“横空出世”,它的背后其实是付出了巨大的代价。
ChatGPT于2022年11月30日发布,短短5天内,它的用户注册量超过100万,2个月内超过了一个亿,令全世界的科技巨头和工程师们怦然心动。
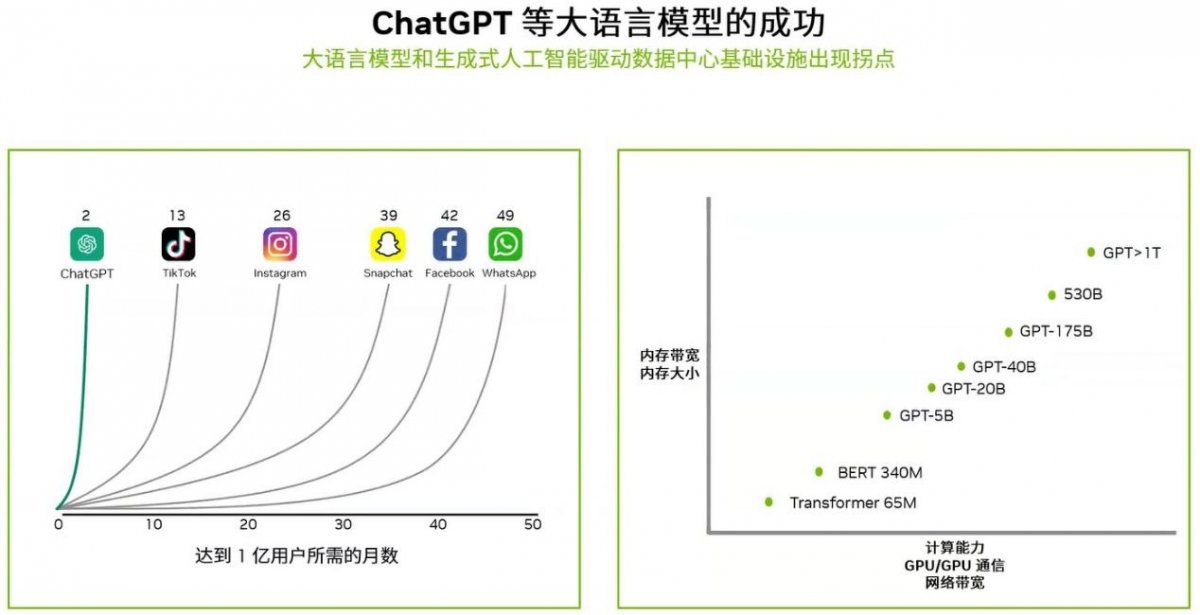
即使当下全球最火爆的视频社交软件TikTok也花了13个月才使注册用户达到1亿
ChatGPT能有如此瞩目的表现,除了技术架构以外,主要归功于持续、巨大的算力投入。
其实,ChatGPT的GPT模型采用的Transformer架构最早是由 Google Brain 的一个团队于2017 年提出。
而GPT模型则于 2018 年由 OpenAI 作为 GPT-1 首次推出,2019 年发展到GPT-2,2020 年发展到GPT-3,2022年发展到 InstructGPT 和 ChatGPT。
GPT模型的迭代发展过程中最重要的一个变化是参数的指数级增长。
GPT-2模型有15亿个参数,GPT-3有1750亿个参数,GTP-3的升级版GPT-3.5有2000亿个参数,GPT-4发布时,OpenAI没有再披露参数的数量、模型的大小以及使用的硬件,很显然其参数数量或许超乎想象。
2020年5月,微软投资了10亿美金与OpenAI独家合作打造了Azure AI超算平台。这个超算平台的性能位居全球前五(处于中国国家超级计算机中心天河 2A 之后,德克萨斯高级计算机中心的 Frontera 之前),拥有超过28.5万个CPU核心、1万个GPU、每个GPU拥有400Gbps网络带宽,算力峰值每秒可以执行 23.5 到 61.4 个万亿浮点运算,主要用于大规模分布式AI模型训练。当时并未对外透露详情,实际上就是为GPT-3模型打造。
即使投入如此之巨,时隔两年多之后, OpenAI才正式推出ChatGPT。
在ChatGPT获得成功之后,2023年1月,微软拟对OpenAI继续追加100亿美金的投入,当时业界猜测这或许是微软想急于摘取胜利果实,获得丰富回报,控制OpenAI的举措,这种余音绕梁不过2月,美东时间3月14日,OpenAI就宣布推出大型多模态模型GPT-4。
可想而知,微软投入的100亿美金大部分将用在GPT-4之中和之后的模型训练上。
在算力方面,据OpenAI团队发表于2020年的论文《Language Models are Few-Shot Learners》中介绍,训练15亿参数的GPT-2模型只需要几十 petaflop/s-day,而训练GPT-3 1750亿参数在预训练期间消耗了数千 petaflop/s-day的算力。
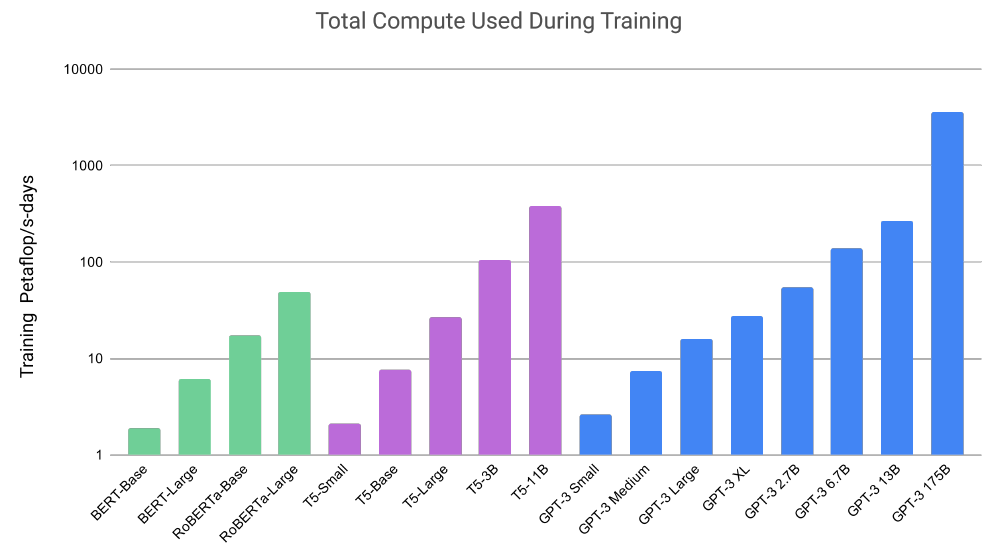
训练期间使用的总算力,来源:OpenAI论文《Language Models are Few-Shot Learners》
而多模态GPT-4及之后的模型,随着参数的增长,所需要的算力激增远超摩尔定律的翻倍增长。
需要的GPU芯片:3万多片/每天
根据Similarweb的数据,截至2023年1月底,ChatGPT官网chat.openai.com网站在2023/1/27-2023/2/3一周吸引的每日访客数量高达2500万。假设以比较稳定的状态,每日每用户提问约10个问题,则每日约有2.5亿次咨询量。
假设每次查询在单台DGX A800上约消耗30.8ms,则一天共需消耗1,025,980个GPU运行小时。
如此算来,平均每天大约需要42,479片NVIDIA的顶级GPU同时进行计算,才可满足当前ChatGPT的访问量。
需要的服务器:约5,343台,成本约为10.7亿美元
选择NVIDIA目前性能最好,也是投入成本产出效益最高的GPU来搭建服务器集群,单机搭载8片GPU,AI算力性能约为5PetaFLOP/s,单机最大功率约为6.5kw,售价约为20万美元/台。
选择标准机柜:19英寸、42U。单个服务器尺寸约为6U,则标准机柜可放下约7个服务器。单个标准机柜的成本为140万美元,构成的性能矩阵为:56个GPU、算力35PetaFLOP/s、最大功率45.5kw。
那么,运营ChatGPT需要的服务器数量为:42,479/8≈5343台,成本约为10.7亿美元。
同时,需要的标准机柜约为764个。
除了上面的硬件投入成本,每天还需要大量的电力投入。
根据上面的测算,运行ChatGPT需要764个标准机柜,消耗的电量约:764*45.5kw*24h=834,288kwh/日。参考Hashrate Index统计,假设美国平均工业电价约为0.08美元/kwh。则每日电费约为834,288*0.08≈6.6万美元/日。
ChatGPT需要不断进化,主要依赖模型的不断迭代升级,这不仅仅需要不断的高额成本投入,也带来了巨大的挑战,主要有三个方面。
1、模型升级,参数呈指数级增长,带宽出现瓶颈
从AI发展与受限制的硬件趋势看到,AI模型每2-3年,规模增长1个数量级以上,芯片峰值算力平均每两年提升3倍,落后于AI模型的发展,然而,内存性能方面落后更多,平均每两年内存容量增长80%;通信带宽方面提升40%,在延迟方面几乎不变,也跟不上模型的发展。
当前,GTP-4模型已经发布,虽然官方没有公布其参数数量,但应该远超过GTP-3的1750亿。这种增长模型的变化,一方面会带来对内存带宽和内存大小的挑战,因为在整个训练过程中需要存储大量的数据,同时也需要处理大量的数据集,所以对内存性能是一个挑战。
另一个重要的方面是GPU与CPU之间的通信带宽问题。在数据中心中,每时每刻都有大量的数据在进行传输,主机在收发数据时,根据传统的架构,需要进行海量的⽹络协议处理。这些协议处理都是由 CPU 完成,消耗了大量的性能和资源,以至于被称为“ Datacenter Tax(数据中心税)”。
而随着AI的快速发展,特别是大语言模型ChatGPT类的人工智能的火爆,巨大的数据量传输和同样海量的处理数据开销增加导致了通信带宽出现瓶颈。
2、电力逐渐无法满足
但OpenAI预计,随着模型迭代,需要的计算资源每三到四个月会翻倍。
按四个月翻倍计算,到2026年初服务器费用将增长512倍,届时需要投入近4000亿美金(还不算过程中的累积投入);每天的耗电量更是达到惊人的3亿度,这个消耗量将是巨大的。
据测算,目前全球数据中心一年使用的电力是200T瓦时,即2000亿度,人工智能运算占用全球电力使用量的2%。随着这类数据中心部署的增长,到2030年,(人工智能)电力的使用份额预计会达到5%。

但是世界各个国家的电力生产能力不同,这将给数据中心带来巨大的挑战。
3、全球节能减排环境治理的要求
与此同时,为了人类的环境,世界各国制定了节能减排计划,要求社会和企业减少碳排放。
其中,中国力争2030年前实现碳达峰,2060年前实现碳中和;欧盟2021年头版《欧盟气候时法》明确“2030年比1990年碳排放减少55%、2050年实际发现碳中和”的目标;美国承诺到2030年,在2005年的水平上减排50%~52%,拜登上台后宣布2050年实现净零排放;日本提出在2013年水平上,至2030年减排45%~50%,韩国最近发布政府方案,争取到2030年较2018年减排11.4%。
而电力行业是碳减排的关键所在。基于麦肯锡全球碳中和模型的测算,为达成1.5摄氏度控温目标,全球电力行业需要在2050年前减少99%以上的碳排放,也就是要达到零碳排放。
一方面是人工智能的不断高速发展,另一方面却是对算力和电力的巨大需求,这实际上与节能减排是一对矛盾。因此,为了绿色地球,人工智能的发展必须要求能够降低能耗,符合大势和人类的发展要求。
同时,尽管ChatGPT推出之后就受到了全球的热捧,但其盈利模式也还在探索之中,这类大语言模型人工智能的发展也面临着投资回报的问题。
从上面的分析看,要调和ChatGPT等人工智能的发展与全球节能减排要求之间的矛盾,需要解决的问题有:内存大小和带宽问题、通信带宽问题、以及电力消耗问题。
要解决这些问题,主要就是要优化驱动ChatGPT等人工智能的芯片和数据中心的问题,提升其性能,减少其能耗。
“横空出世”的DPU——驱动数据中心网络的引擎
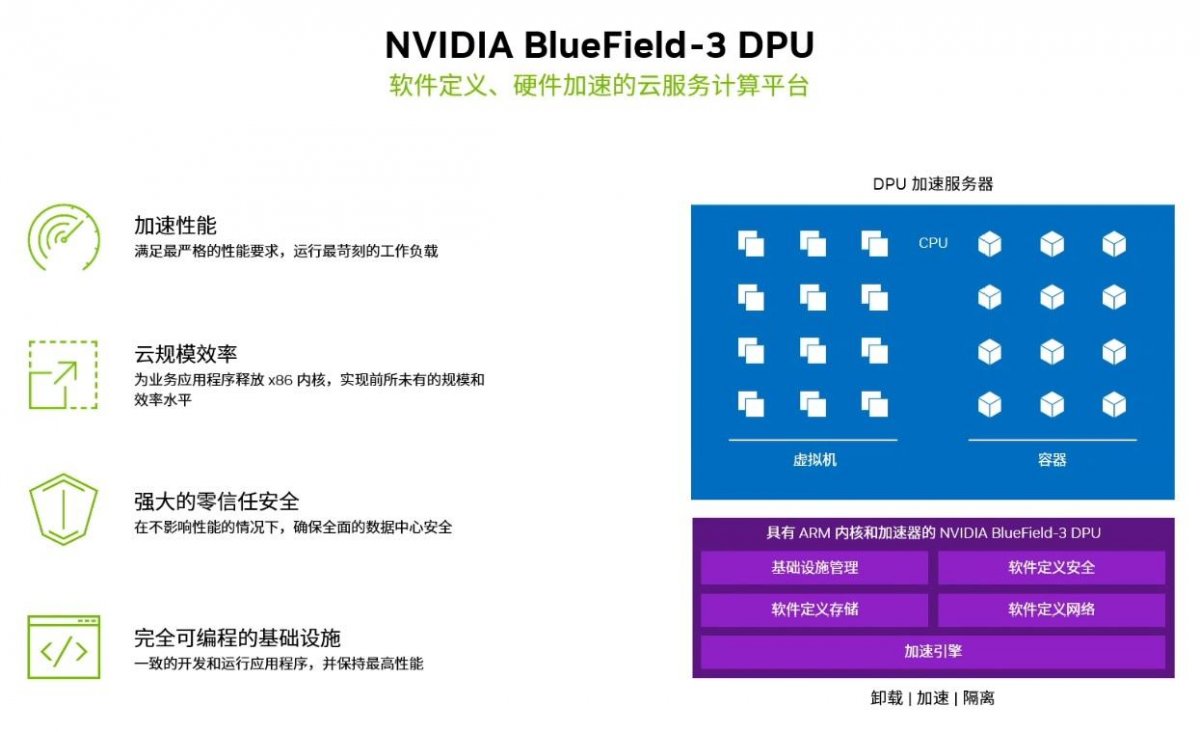
其实,在ChatGPT爆发之前,GPU巨头NVIDIA就已经着手解决这些问题。他们采用的方式正是基于上面的问题和痛点所在。内存方面,不断提升内存速度和带宽,升级内存架构。NVIDIA在其擅长的GPU方面不断推陈出新,更重要的举措是在新的通信带宽领域推出了DPU,能够大大缩减成本,提升性能、降低能耗。
2019 年 3 月,NVIDIA花费 69 亿美元收购了以色列芯片公司 Mellanox 。NVIDIA将 Mellanox 的 ConnectX 系列高速网卡技术与自己的已有技术相结合,于 2020 年正式推出两款 DPU 产品:BlueField-2 DPU 和 BlueField-2X DPU 。这些产品一经推出就得到云服务提供商以及许多原设备制造商和软件合作伙伴的支持,因为其解决了数据中心带宽瓶颈的问题。
2021年,科技界首次详细介绍了 NVIDIA BlueField DPU(数据处理器)的内部结构。

这是用于加速现代数据中心的芯片—— 一个由硬件加速器和通用 ARM 核心组成的阵列,可用于加速网络、安全和存储工作。
这个架构推出后,被应用于几个全球最大的云计算平台以及一台 TOP500 超级计算机,并与新一代防火墙集成。它很快就在多家顶级 OEM 的系统中被使用,这些系统拥有十多个其他合作伙伴提供的软件支持。
NVIDIA 创始人兼首席执行官黄仁勋将 DPU 描述为:“未来计算的三大支柱之一,CPU 用于通用计算,GPU 用于加速计算,而 DPU 则用于数据中心的数据移动和处理。”
推动数据中心转型
2021年前后,云计算和 AI 正在突破数据中心规模和性能的界限,在这个关键时间点,全球主要的科技巨头,包括百度、Palo Alto Networks、Red Hat和VMware等行业领导者,均采用了 BlueField DPU构建高性能、零信任的数据中心,并采用最新的BlueField-3 DPU为下一波的应用程序提供强力支持。
2021年,是NVIDIA BlueField DPU大放异彩的一年。
百度为其具有扩展性的裸机云基础设施部署了 NVIDIA 的 BlueField DPU,可以对硬件实现直接访问,性能稳定而又可预测。传统的裸机基础设施缺乏虚拟化云提供的运行灵活性和敏捷性。通过使用 BlueField DPU高速网络和租户隔离的能力,百度可以轻松地向中国为数众多的客户提供裸机计算实例。NVIDIA 的 BlueField DPU使百度将裸机从硬件定义的服务器基础设施转变为软件定义、硬件加速的云平台。
Red Hat与 NVIDIA 密切合作,部署在包含 50000 个节点的机组上,实现了 GPU 加速的 AI 计算并推动整个堆栈的创新,使这种尖端的基础设施可通过 BlueField DPU 软件定义、硬件加速的高效引擎,节省高达 7000 万美元。
为满足 5G 对数据处理的严格要求,Palo Alto Networks 集成了搭载 NVIDIA BlueField DPU 的新一代行业领先的防火墙,其由软件定义、硬件加速的防火墙架构,可提供 100Gb/s 的线速安全处理。
VMware 与 NVIDIA 携手为 30 万余家使用 VMware 虚拟化平台的机构组织构建高性能、更安全、更高效的 AI 就绪型云平台。
提升数据中心效率
NVIDIA DPU与爱立信、Red Hat 和 VMware 合作进行的一系列测试显示,使用 NVIDIA BlueField-2 DPU 的服务器的功耗最多可降低24%。在某个测试案例中,这些服务器的性能相比于仅使用 CPU 时提升了 53 倍。
数据中心能够变得更加环保,实现节能减排,这要归功于 DPU加速的高效网络。
电力成本减少近 200 万美元
爱立信的研究人员测试了运营商是否可以使用智能网卡(具有 DPU 功能的网卡)来减少这些大型工作负载的功耗。在测试中,他们让 CPU 减速运行或进入睡眠状态,同时使用一块 NVIDIA ConnectX 智能网卡处理网络任务。
结果表明,在满负荷网络上运行的服务器的 CPU 能耗从 190 瓦降至 145 瓦,下降了 24%。单靠应用这一个 DPU ,一个大型数据中心可在三年间削减近 200 万美元的电力成本。

爱立信在三种场景下在 DPU 上运行 5G 网络用户平面功能
爱立信 CTO Erik Ekudden强调了这项工作的重要性,他写道:“电信服务供应商正越发急迫地想要找到并实施能够降低网络能耗的创新型解决方案。” 他认为 DPU 技术 “可在各种流量条件下节约能源”。
用度减少 70%,性能提升至原来的 54 倍
在 Red Hat OpenShift 上的 DPU 测试结果更为惊人。
在测试中,BlueField-2 DPU 需处理用于管理便携式应用程序和代码包所需的各项虚拟化、加密和网络任务。
DPU 将网络对于 CPU 的需求降低了 70%,从而释放出大量 CPU,用于运行其他应用。此外,它们还使网络任务的速度大幅提升,达到了原来的 54 倍。
BlueField-3 DPU的神秘面纱,伴随着DOCA揭开
类似摩尔定律,BlueField DPU每 18 个月会更新一代。BlueField-2的下一个版本BlueField-3,是最新的DPU。NVIDIA 创始人兼首席执行官黄仁勋先生在 GTC 2021 主题演讲中揭开了 BlueField-3 的神秘面纱,这是公司历经多年创新的结晶。

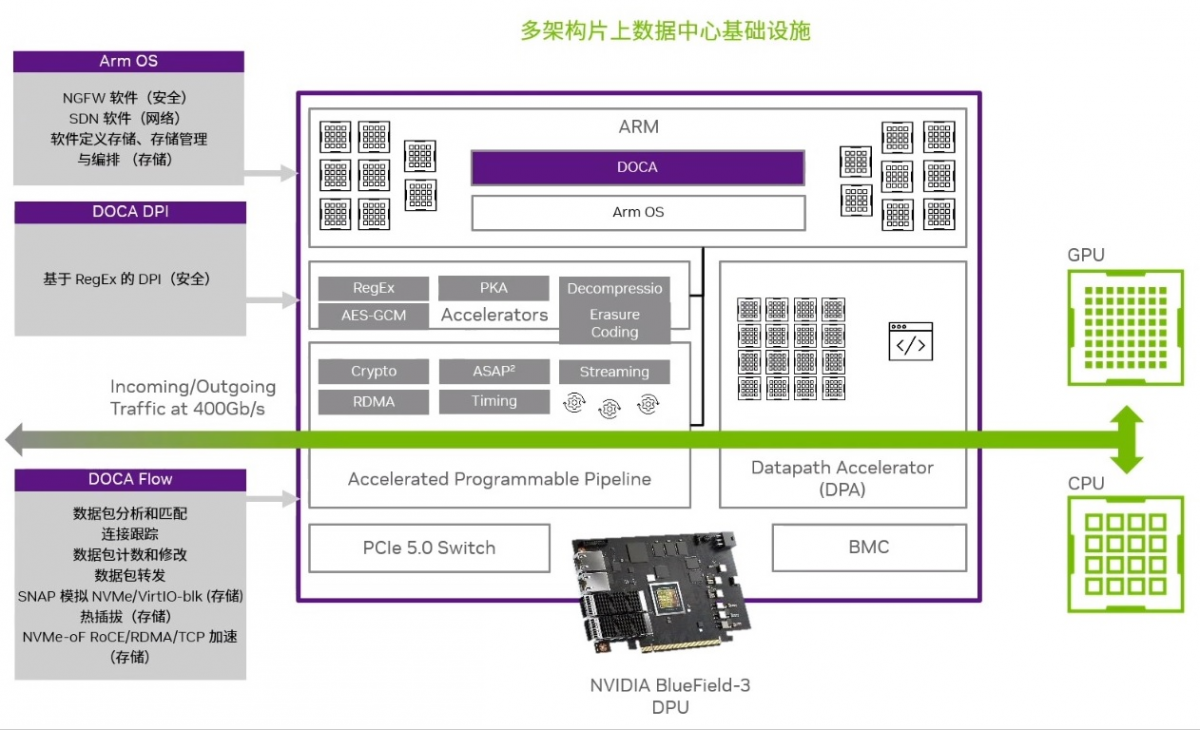
NVIDIA 的 BlueField-3 DPU 率先支持 400Gb/s 以太网和 InfiniBand 网络,其处理能力高达上一代产品的 10 倍。

黄仁勋还宣布,NVIDIA 推出的DOCA是功能强大的应用程序框架,可支持开发者在 NVIDIA 的 BlueField DPU 上迅速创建应用程序和服务。每一代 BlueField DPU 都支持 DOCA,随着每代 DPU 的演进,原先开发的应用程序可以完全兼容。
有了DOCA,对于客户来说,这意味着在目前 BlueField DPU上运行的应用程序和数据中心基础设施,在不久的未来将能不加修改地加速运行在 BlueField-3 DPU上。
NVIDIA介绍DOCA是“为DPU注入了灵魂”,实际上DOCA是NVIDIA针对DPU开发者提供的软件开发框架,是一个一站式平台并有活跃的社区。说起NVIDIA的开发平台和社区,工程师们就会想起十多年前NVIDIA 举办的第一次CUDA活动。
CUDA最初的使命与崛起
2006年,NVIDIA CUDA(Compute Unified Device Architecture)架构问世,与此同时,NVIDIA图形处理器出货量达到5亿台。

2007年,在美国加州圣克拉拉市,NVIDIA举办了第一届CUDA(Compute Unified Device Architecture)技术大会,这是一种并行计算平台和编程模型,可用于利用NVIDIA GPU的强大计算能力。CUDA使开发人员能够使用C语言,C ++,Fortran等编程语言来编写GPU加速的应用程序。
在第一届CUDA技术大会上,NVIDIA展示了许多基于CUDA的应用程序,包括物理模拟,图像处理和生物信息学。此外,NVIDIA还介绍了CUDA的架构和编程模型,并提供了一些实用的编程技巧和最佳实践。
自那时以来,CUDA已成为一种广泛使用的GPU编程平台和编程模型,用于各种科学,工程和商业应用程序。
2008年NVIDIA推出CUDA SDK2.0版本,大幅提升了CUDA的使用范围。使得CUDA技术愈发成熟。
2009年,NVIDIA在第一届 GPU 技术大会上发布了 FERMI 架构,这是新一代CUDA GPU架构。
2011年,清华大学微电子研究所副教授邓仰东在国内正式全面介绍CUDA,邓教授也成为国内系统化讲授CUDA技术的第一人。
但即使如此,当时的CUDA也远远没有现在这么火热,因为,那时的CUDA主要还是用于GPU图形处理器的加速开发,人工智能还只是在很小的范围内萌芽,远没有出现当今各行各业AI化和ChatGPT带起的火热浪潮。
截止2023年初,以CUDA开发为主的NVIDIA开发者社区,中国注册开发者人数超过88万人,全球总的注册开发者人数400多万,占超过20%的比例。
当前,CUDA社区的开发者大部分都是在进行人工智能的设计与研发,处于全球最顶尖的人工智能工程师行列。
如今,NVIDIA又针对DPU推出了DOCA开发平台和社区,历史会不会重演呢?
DOCA露面
2021年Hot Chips大会上,NVIDIA BlueField DPU”横空出世“,让科技界欢呼,而让处理器架构师着迷的好消息是用户只需要将现有的软件对接熟悉的高级软件接口,就可以使用 DPU,他们不需要很多软件移植的额外工作。
这些接口 API 都集中在一个被称为NVIDIA DOCA的软件栈中。这个类似于CUDA的栈包括了驱动程序、库、工具、文档、示例应用和运行时环境,可在整个数据中心的数千个 DPU 上进行配置、部署和编排服务。
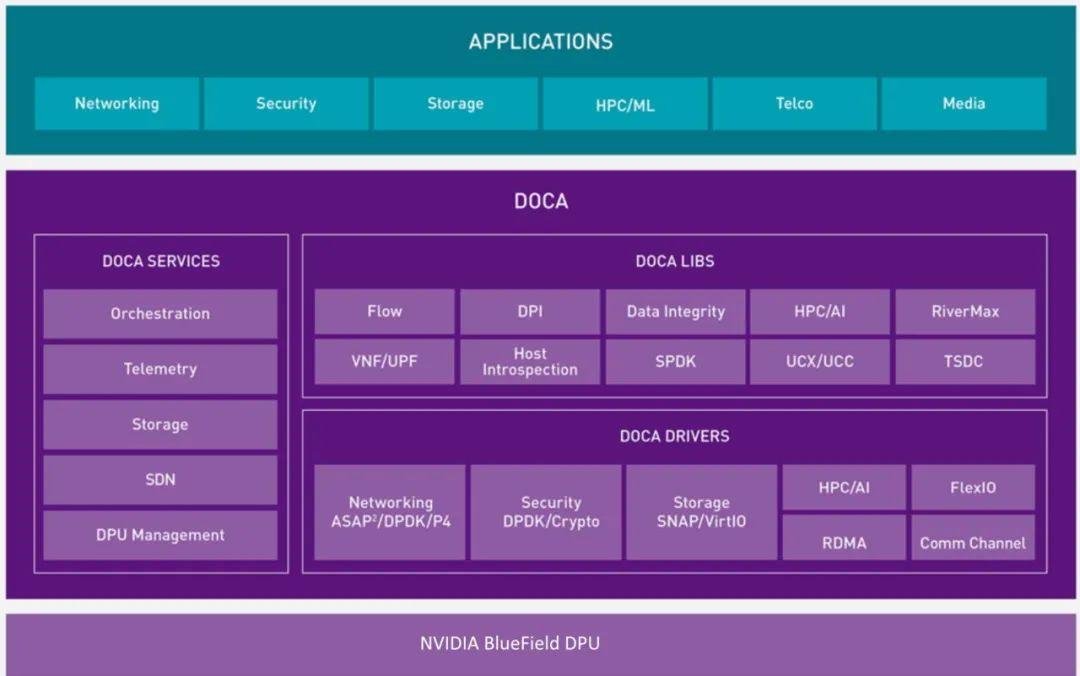
DOCA 提供一个用于在 DPU 上快速开发网络、存储和安全应用的软件平台
2022 年 4 月 16 - 17 日,经过紧张激烈的竞赛,首届 NVIDIA DPU 中国黑客松圆满收官,这是NVIDIA为其DOCA平台和社区举办的一次竞赛活动。
DPU首届中国黑客松竞赛
报名首届 NVIDIA DPU 中国黑客松竞赛的队伍有69支,其中10 支被入选最终竞赛。

从2022年 4 月 16 日上午 9 点正式开始,10支参赛队伍经过 24 小时的紧张软件编程与系统开发,于 17 日上午向中国评委呈现最终项目成果并进行评分。最终项目成果同时被送至国际评委进行评分,通过综合国内和国际评委的评分,最终 4 支队伍脱颖而出,获得这次黑客松竞赛大奖。
其中冠军队为PDSL 团队,队长:杨豪迈,队员:郭一兴、刘鹏宇。
在这次黑客松竞赛中,开发者通过 NVIDIA DOCA 软件框架构建创新的数据中心加速应用程序,支持用于人工智能、网络、存储和安全的 NVIDIA BlueField DPU 卸载、加速和隔离功能。这种新的加速将引领新一代人工智能驱动的数据中心及云计算变革浪潮。
当时,全球有 2000 多名 DOCA 早期开发者,其中42%的开发者来自中国。
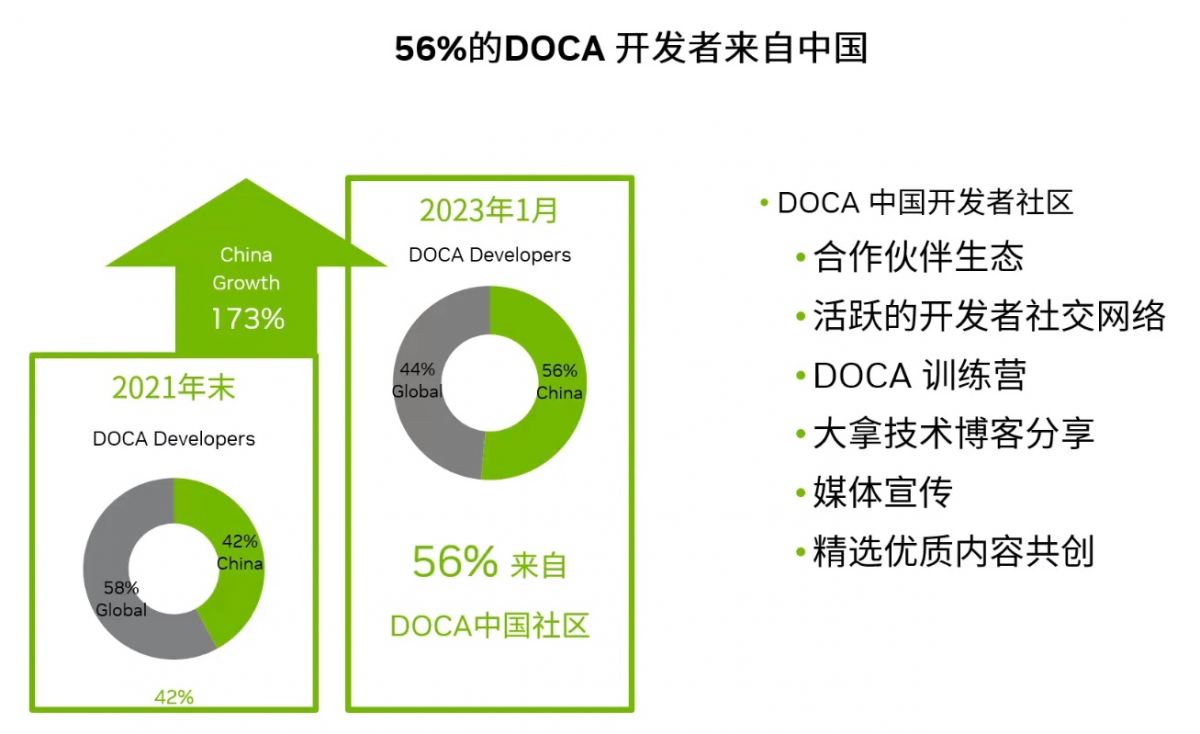
随着DOCA的继续发展,半年多以后,截止2023年1月,全球有超过4600名开发者,其中56%来自中国。中国的开发者有来自互联网大厂、创业公司、企业和学校,还有来自大学的教授等等。
DOCA到底是什么?
DOCA是NVIDIA提供的免费的用于BlueField DPU的软件开发框架,可以卸载、加速和隔离基础设施操作,支持超大规模、企业、超级计算和超融合基础设施,为BlueField DPU 硬件迭代提供软件兼容性。
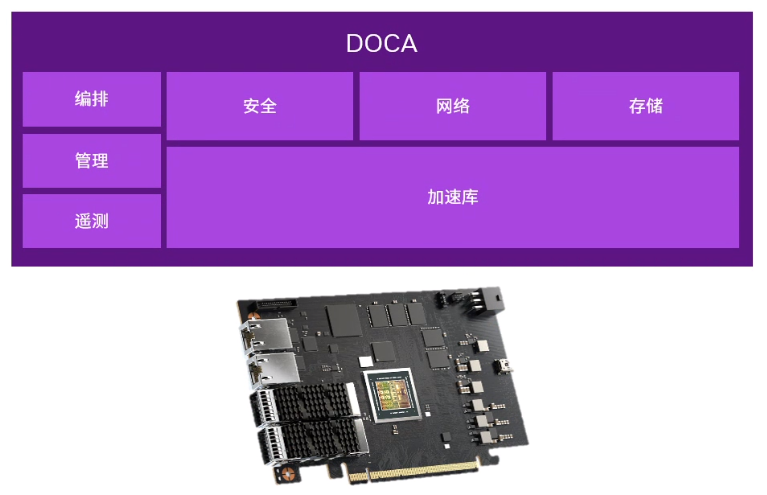
DOCA提供了SDK和RUNTIME组件
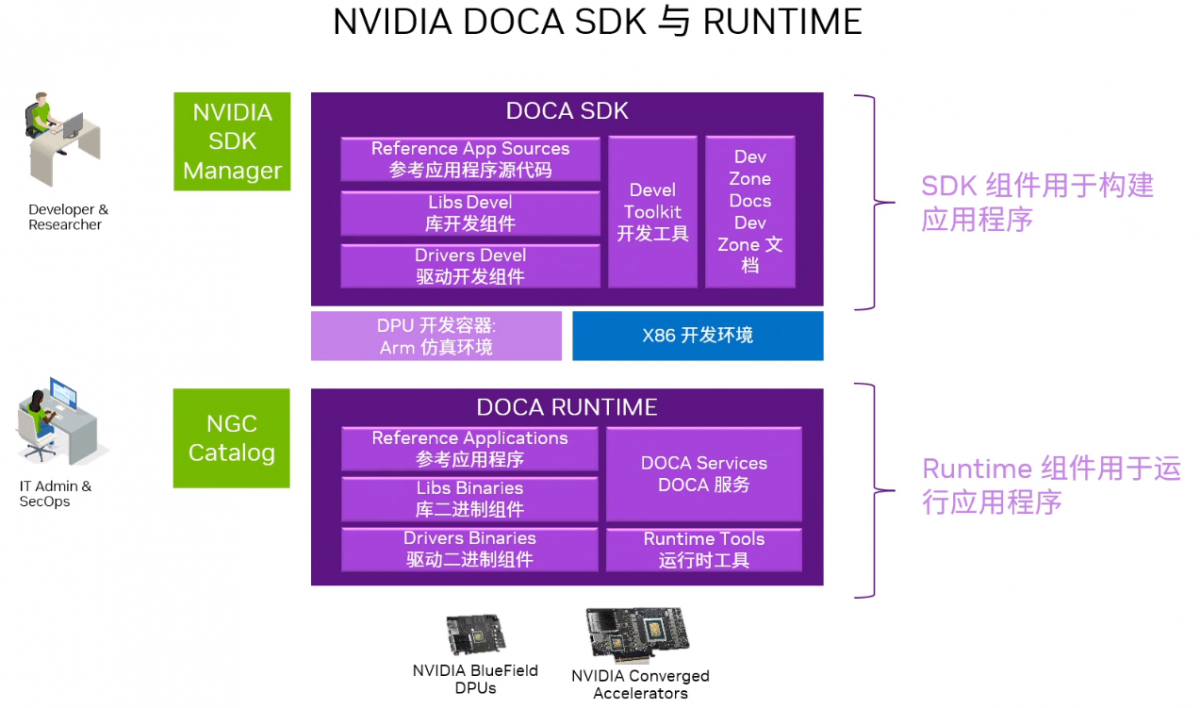
同时,DOCA提供了服务组件,可以加速数据中心服务(例如: 遥测),简化部署,从NGC目录获取并快速启动,在各种环境中移植,通过内置的 DOCA Runtime 提供基础服务容器等等。
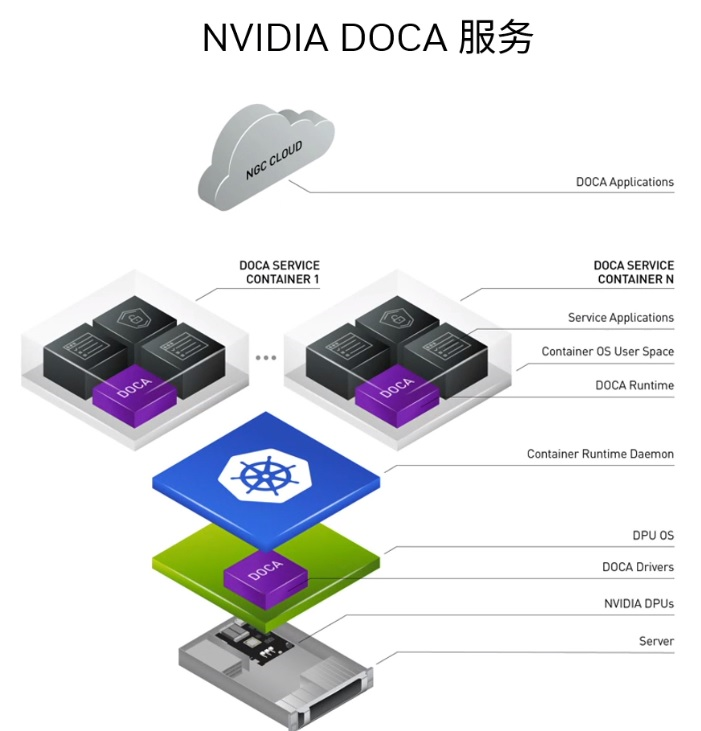
DOCA是NVIDIA为其DPU打造的可编程软件平台:
如果要用一句话来描述DOCA的话,那就是:DOCA之于DPU,正如 CUDA 之于 GPU。
DOCA,或缔造下一个王者
CUDA当时推出来仅仅是为了进行GPU图形加速,以给游戏和图形工作程序更好的体验。但是,随着GPU芯片在深度学习等人工智能领域的应用,CUDA一跃成为了最前沿的技术开发平台,目前,CUDA已经是全球最火热也最有价值的编程平台之一。
DOCA会不会成为下一个王者呢?
随着GPU硬件与人工智能进入深水区,CUDA也不可避免的要进行二次深度沉淀,同时,基于CUDA的开发也已经很成熟。人工智能的硬件发展也处于一个亟待突破的瓶颈期。
DOCA是为了更快更高效的提升人工智能的效益与性能,能够解决当前最重要的成本投入与性能瓶颈问题,也就是解决人工智能算力与性能的痛点。这也是目前全球微软、谷歌、亚马逊、百度等巨头和人工智能细分垂直领域的企业在人工智能开拓方面的痛点。
然而,基于AI本身的特点,譬如ChatGPT就能自行进行编程,DOCA会不会很快就被AI所取代呢?
笔者认为,DOCA在目前阶段还不可能被替代,因为所积累的数据和程序不够,无法满足AI学习达到“自学成才”的效果。
未来,DOCA之于DPU,或许正如CUDA之于GPU一样,会缔造下一个编程王者。
NVIDIA在2000年前还只是一个做图形处理器的公司,从1993年成立到1999年这段时间,在显卡市场中还没有占据什么领先优势。
当NVIDIA于1999年8月推出GeForce 256显卡之后,打开了个人电脑游戏加速市场,很快就占据了GPU市场70%以上的份额。在此之前,GPU显示芯片都属于固定功能的芯片,而GeForce 256的出现,成为了第一款“集成了转换、照明、三角形设置/剪裁和渲染引擎的单芯片处理器”,能够每秒处理至少1000万个多边形,让GPU可以从CPU手里接管大量几何运算的工作,解决通用计算无法解决的问题,极大地推动了PC游戏、创意设计等对GPU的需求。
这可能是NVIDIA对GPU市场的第一次“非预见性变革”。
2006年,英伟达推出了通用计算架构CUDA,以及通用计算硬件Tesla GPU。但在当时,深度学习只有一些大型企业、研究机构需要GPU来进行药物发明、天气建模、金融分析等高性能计算任务。
2009年,NVIDIA举办了首届“GPU技术会议”,向“使用GPU解决重要计算工作的开发者、工程师和科研人员”推广。
2012年深度学习三巨头之一Geoffrey Hinton及其学生Alex,使用GPU来加速训练深度神经网络,在ImageNet竞赛中一鸣惊人,掀开了人工智能历史上第三次浪潮的大幕。
在推出GPU图形卡的时候,很少有人想到它能够用于深度学习、神经网络等人工智能前沿技术,正是由于有了CUDA,以及与开发人员的互动,CUDA与GPU一起推动了人工智能必需的高速计算的发展,大大加速了人工智能发展的进程。
这应该算是NVIDIA对人工智能算力的第二次“非预见性变革”。
人工智能在沉淀发展了几年之后,ChatGPT“横空出世”,一经推出,就受到了全世界的高度关注和热捧。然而,在高度智能的背后,是巨大的成本和算力投入,这与企业的ROI和全球节能减排的目标是矛盾的。
这时,NVIDIA把早已研发的秘密武器——DPU和DOCA推出,它们能够大大缩减人工智能计算的成本,提升计算效能,解决当下痛点。
或许,DPU将是NVIDIA对高速计算的第三次变革,这一次,属于“预见性变革”。
用黄仁勋本人的说法,“NVIDIA历史上几次具有里程碑意义的关键技术推出,背后其实都是对自家 GPU 技术的发展成果进行了“泛化”(generalize),发现它可以做更多不同的事情”。
而这些,都已经或正在成为计算时代的变革力量。
人工智能在ChatGPT的火爆带动之下再次迎来新的浪潮,智能物联网(AIoT)的发展也正如日中天。AIoT市场持续扩大,主要得益于AIoT技术和产品的不断演进,并持续满足市场需求。未来几年,在产业驱动、消费驱动以及政策驱动的多重因素助推下,AIoT产业仍将保持高速增长。长期来看,AIoT产业驱动应用市场潜力巨大,将成为远期增长点。
为了帮助行业上下游企业更好地把握AIoT市场发展商机,全球领先的专业电子机构媒体AspenCore将携手深圳市新一代信息通信产业集群联合主办【2023国际AIoT生态发展大会】,将于2023年6月8日在深圳南山科兴科学园国际会议中心盛大举行!

预登记通道现已开启,长按立即报名参会!
 最前沿的电子设计资讯
最前沿的电子设计资讯

