
从云端的大数据处理到边缘端的关键字识别和图像分析,人工智能(AI)应用的爆发式增长,正在推动专家们争先恐后地开发最佳架构来加速机器学习(ML)算法的处理。由于新兴的解决方案多种多样,因此在选择硬件平台之前,设计人员必须对应用及其需求进行明确定义。
在许多方面,大家扎堆进入AI加速领域,类似于90年代末和2000年代初的DSP淘金热。那个时期,随着有线和无线通信的兴起,人们纷纷推出高性能的DSP协处理器以应对基带处理的挑战。与DSP协处理器一样,AI加速器的目标是找到执行海量运算所需最快、最节能的方式。
神经网络处理背后的数学,涉及统计学、多元微积分、线性代数、数值优化和概率等。虽然很复杂,但它也是高度可并行化的。事实上,这种可并行化令人尴尬,这意味着,与分布式计算不同,在重新组合通路的输出并产生输出之前,它很容易被分解为没有分支或依赖的并行通路。
在各种神经网络算法中,卷积神经网络(CNN)特别擅长于做对象识别等任务——过滤掉图像中的干扰而识别出感兴趣的对象。CNN接收数据形成多维矩阵(称为张量),将超出第三维的每个维度都嵌入到子数组中(图1)。每个添加的维度称为“阶”,因此,五阶张量会有五个维度。

图1:CNN将数据摄入作为张量,即可被可视化为三维立方体的数字矩阵(数据集),但在每个数组中还有一个子数组,该数字定义了CNN的深度。(图片来源:Skymind)
这种多维分层对于理解CNN所需加速的本质很重要。卷积过程使用乘法在数学上将两个函数“卷绕”到一起,因此广泛使用乘法累加(MAC)数学。例如,在对象识别中,一个函数是源图像,另一个函数是用于识别特征(然后将其映射到特征空间)的过滤器。每个过滤器都要多次执行这种卷绕,以便识别图像中的不同特征,因此数学变得非常重复并且令人尴尬(或令人愉悦)的可并行化。
为此,一些AI加速器的设计采用多个独立的处理器内核(高达数百或上千个),与存储器子系统一起集成在单个芯片中,以便减轻数据访问延迟并降低功耗。然而,由于业界已设计了图形处理器(GPU)来对图像处理功能进行高度并行处理,因此它们对于AI所需的这种神经网络处理也可以实现很好的加速。人工智能应用的多样性和深度,特别是在语音控制、机器人、自动驾驶和大数据分析等方面,已经吸引了GPU供应商将重点转移到AI处理硬件加速的开发。
然而,AI硬件加速的问题在于有如此多的数据,并且所需的准确性和响应时间又千差万别,因此设计人员需要明确他们需要选择哪种架构。例如,数据中心是数据密集型的;因为其重点是尽可能快地处理数据,所以功耗并不是一个特别敏感的因素——尽管能源效率有利于延长设备使用寿命,降低设施的整体能耗和冷却成本,这合乎情理。百度的昆仑处理器耗电量为100W,但算力高达260TOPS,这就是一款特别适合数据中心应用的处理器。
我们看一个“低端”的例子。像关键词语音识别这样的任务,需要与云端建立连接,以便使用自然语言识别来执行进一步的命令。这种任务现在在基于GreenWaves Technologies公司GAP8处理器的电池供电型边缘设备上就可以实现。这种处理器是为边缘应用设计的,因此强调超低功耗。介于中间的应用,比如自动驾驶汽车中的摄像头,则需要尽可能接近实时地做出响应,以便识别道路标志、其他车辆或行人,而同时仍然需要最小化功耗,特别对于电动汽车,这种情况下也许应该选择第三种方案。在此类应用中,云端连接也很重要,以便及时更新所使用的模型和软件,以确保持续性地提高准确度、响应时间和效率。
鉴于软件和硬件方面的技术在迅速发展且不断更新,不建议将AI神经网络(NN)加速器集成到ASIC或是系统级封装(SiP)中——尽管这样的集成具有低功耗、占用空间小、成本低(大批量时)和存储器访问速度快等优点。加速器、模型和NN算法的变动太大,其灵活性远远超过指令驱动的方法,而只有像英伟达这样的技术先进而又资金雄厚的玩家,才能够担负得起,而在硬件上根据特定方法进行迭代。
这种硬件加速器开发工作的一个很好的例子就是,英伟达在其Tesla V100 GPU中增加了640个Tensor内核。每个内核在一个时钟周期内可以执行64次浮点(FP)融合乘加(FMA)运算,可为训练和推理应用提供125TFLOPS的算力。借助该架构,开发人员可以使用FP16和FP32累加的混合精度进行深度学习训练,而获得比英伟达自己的上一代Pascal架构高3倍的运算速度。
混合精度方法很重要,因为长期以来人们已经认识到,虽然高性能计算(HPC)需要使用32~256位FP进行精确计算,但深度神经网络(DNN)不需要这么高的精度。这是因为经常用于训练它们的反向传播算法对误差具有很强的弹性,因此16位半精度(FP16)对NN训练就足够了。此外,存储FP16数据比存储FP32或FP64数据的存储器效率更高,从而可以训练和部署更多的网络,而且对许多网络来说,8位整数计算就足够了,对准确性不会有太大影响。
这种使用混合精度计算的能力,在边缘侧变得更为实用。当数据输入的来源是低精度、低动态范围的传感器——比如温度传感器、基于MEMS的惯性测量单元(IMU)和压力传感器等——以及低分辨率视频时,开发人员可以以精度换取低功耗。
可扩展处理的概念已经扩展到更广泛的网络——可以采用雾计算的概念来弥补边缘和云端之间的能力差距,而在网络的最佳位置执行所需的处理。例如,可以在本地物联网(IoT)网关或更接近应用现场的本地服务器上进行NN图像处理,而不必在云端进行。这样做有三个明显的好处:可以减少由于网络延迟造成的时延,可以更安全,还可以为必须在云端处理的数据释放可用的网络带宽。在更高的层面上,它一般也更为节能。
因此,许多设计师正在开发内置摄像头、图像预处理和NN AI信号链功能的独立产品,这些产品仅在相对闭环的操作中呈现输出,例如已识别标志(自动驾驶汽车)或人脸(家庭安防系统)。
在更极端的情况下,例如在偏僻或难以到达的地方,采用电池或太阳能供电的设备,可能需要长时间地进行这种处理。
为了帮助降低这种边缘AI图像处理的功耗,GreenWaves Technologies公司的GAP8处理器集成了9个RISC-V内核。其中一个内核用于硬件和I/O控制功能,另外八个内核围绕共享数据和指令存储器形成一个集群(图2)。这种结构形成了CNN推理引擎加速器,具有额外的RISC-V ISA指令来增强DSP类型的运算。
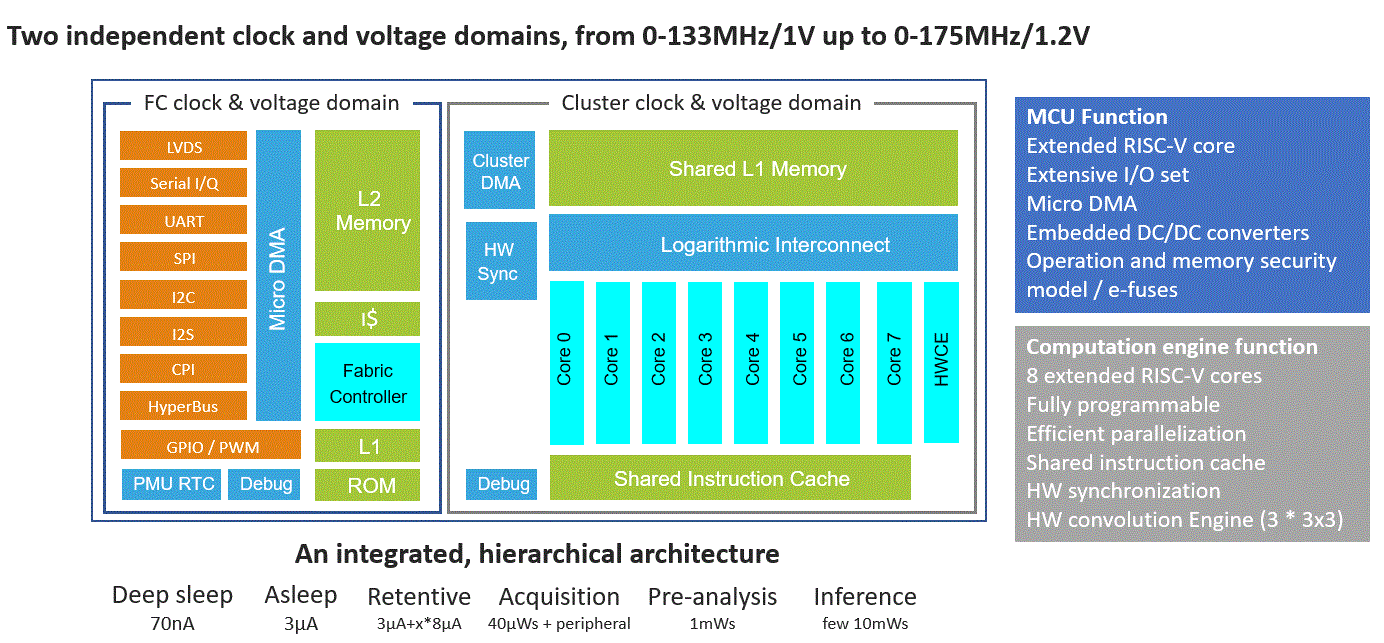
图2:GreenWave的GAP8采用9个RISC-V处理器,针对网络边缘智能设备上的低功耗AI处理进行了优化。(图片来源:GreenWaves Technologies)
GAP8设计用于网络边缘的智能设备,在功耗仅为几十毫瓦(mW)的情况下即可实现8GOPS运算,或者在1mW时可实现200MOPS运算。它完全可以用C/C++编程,最小待机电流为70nA。
RISC-V开源硬件模式最初遭到质疑,因为它需要一个可靠的用户社区,能提供一套丰富的支持工具和软件。但随着该架构通过各种测试芯片和硬件实现而吸引更多开发者加入,这种质疑正在逐渐消退。
RISC-V的吸引人之处在于,它正在成为Arm处理器的强劲对手,特别是在超低功耗、低成本应用中。当谈到低成本时,每一分钱都要考虑,因此免费总比支付许可费好。
然而,虽然GAP8可以节能并且针对边缘NN处理进行了高度优化,但从系统开发的角度来看,仍然需要考虑外设部分,例如摄像头传感器本身和网络通信接口,以及是有线还是无线等。视系统通信和处理图像的频率不同,这些功能占用的功耗比例可能较高。根据GreenWaves的说法,GAP8若采用3.6Wh的电池供电,每隔3分钟对一张QVGA图像进行分类,则可以持续工作长达10年之久,但这个数字没有考虑整体系统中其他因素的影响。
GreenWaves将其GAP8处理器与基于Arm Cortex-M7内核、工作频率为216MHz的意法半导体STM32 F7处理器进行了直接比较(图3)。两者针对CIFAR-10图像进行了训练,权重量化为8位定点。
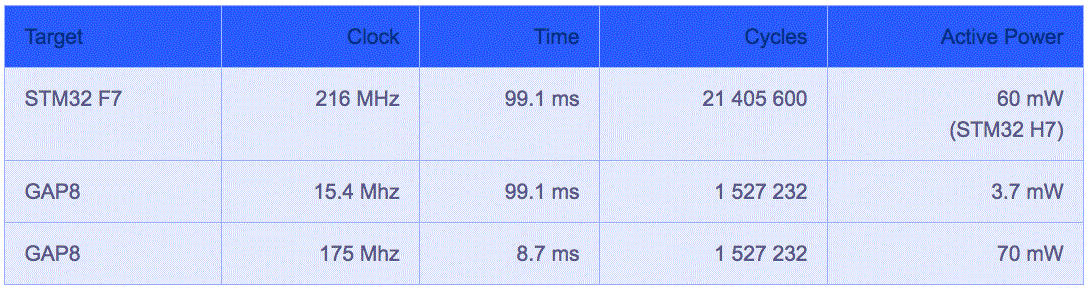
图3:GreenWaves Technologies将其GAP8与基于Arm Cortex-M7内核的STM32 F7处理器在针对CIFAR-10图像进行训练后进行了直接对比。(图片来源:GreenWaves Technologies)。
虽然GAP8由于其八核架构,显示出效率更高、时钟速率更低并能够以更少的周期实现推理,但Arm自身也没有停滞不前。Arm已发布了针对移动设备和其他相邻网络边缘应用的ML(机器学习用)处理器,其应用场景包括AR/VR、医疗、消费电子产品以及无人机等。其架构采用固定函数引擎来执行CNN层,并采用可编程层引擎来执行非卷积层以及所选基元和算子的实现(图4)。
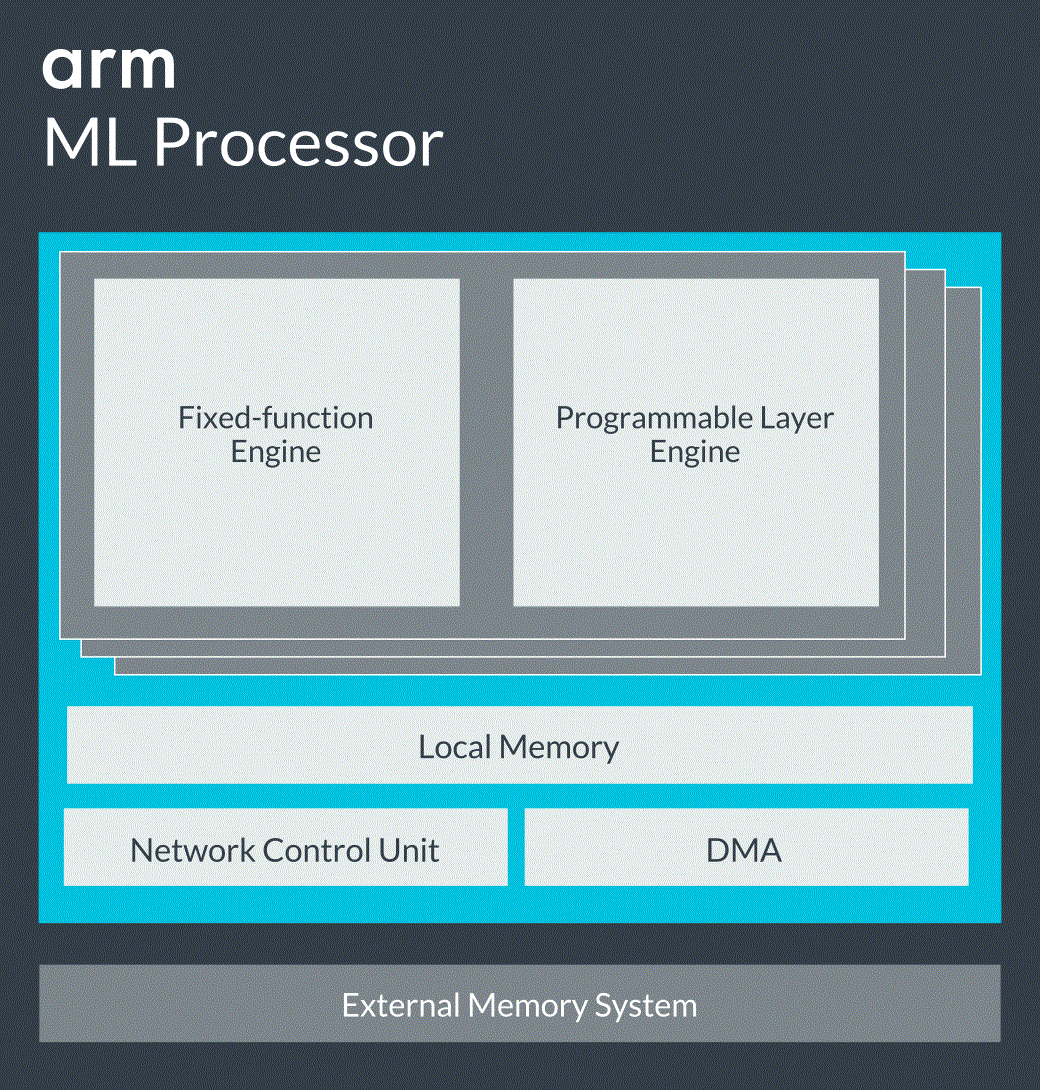
图4:Arm的ML处理器设计用于CNN型固定函数以及可编程层引擎的低功耗边缘处理。(图片来源:Arm)
有趣的是,ML处理器基于高可扩展性的架构,因此同一处理器和工具可用于开发从物联网到嵌入式工业和交通,一直到网络处理和服务器等各种应用,算力要求从20MOPS到超过70TOPS不等。
如果开发团队希望从云端往下扩展,或从边缘往上扩展,那么这种可扩展性比较适合之前讨论的雾计算概念。此外,该处理器本身与主流NN学习框架紧密集成,例如Google的TensorFlow和TensorFlow Lite,以及Caffe和Caffe 2。它还针对Arm Cortex CPU和Arm Mali GPU进行了优化。
通过ML处理器,Arm还强调了异构方法对于面向AI的NN的重要性,但仅限于其CPU和GPU的狭窄范围内。从更广泛的角度来看,英特尔的OpenVINO(视觉推理和神经网络优化)工具包可以实现异构混合架构的开发,包括CPU和GPU,以及FPGA,当然还有英特尔自己的Movidius视觉处理器(VPU)和基于Atom的图像处理器(IPU)。借助通用API并优化调用OpenCV和OpenVX,英特尔声称其深度学习性能可以提高19倍。
异构方法对于面向AI的NN处理既有益又必要。它从头开始设计,打开了更多的处理可能性和潜在的优化机会。但是,许多嵌入式系统已经部署了相关的硬件,通常是MCU、CPU、GPU和FPGA的混合,因此如果有开发工具可以在这样的已设置硬件基础上开发AI应用,并通过单个API进行相应的优化(假设像OpenVINO这样的工具包与底层硬件兼容的话),这将可以解决很多问题。
在今年7月北京举行的百度Create 2018大会上,百度宣布推出了昆仑AI芯片——这是中国首个云到边缘的AI芯片组,包括818-300训练芯片和818-100推理芯片(图5)。

图5:百度昆仑是中国第一个云到边缘的AI处理器芯片组,虽然其架构的具体细节尚未公布,但它要比百度2011年发布的基于FPGA的AI加速器快30倍。(图片来源:百度)
昆仑芯片比百度2011年发布的基于FPGA的AI加速器快30倍,高达260TOPS@100W。它将采用三星14nm工艺,内存带宽为512GB/s,虽然百度尚未公布其架构参数,但它可能包含数千个内核,可为百度自己的数据中心进行海量数据的高速并行处理。百度也有计划针对各种客户设备应用和边缘处理应用推出低性能版本。
百度的昆仑紧随谷歌5月份发布的TPU 3.0之后,谷歌没有透露细节,只说它比去年快8倍,达到100PFLOPS。
虽然还有许多其他新兴的NN处理架构,但如果对“计算能力对实时性能”要求有合理期望的话,也有许多当前可用的处理器和套件完全能够满足边缘计算的要求。例如,基本的家庭安防系统可能包括一个摄像头,它可以进行人脸识别处理并通过Wi-Fi连接到家庭网关或路由器,而使用目前市面上可用的处理器或套件就可以实现它。
对于想要尝试这种设计的开发人员来说,没有必要从发明轮子开始。相反,应该选择一个已经得到广泛支持的平台,包括各种CPU、视频和图形GPU、快速存储、内置的无线和有线通信模块,以及合适的操作系统支持和广泛且活跃的用户生态系统。
例如,恩智浦半导体的i.MX 8M就是个合适的起点(图6)。这实际上是个处理器系列,具有多达四个1.5GHz Arm Cortex-A53和Cortex-M4内核。它有两个GPU类型的处理器,一个用于图像预处理,另一个用于NN加速。

图6:恩智浦的i.MX 8M解决了快速启动开发的问题,同时还可以使用基于Arm的处理器来扩展AI应用。(图片来源:恩智浦半导体)
另一个关键设计要求是现场的使用寿命要足够长,因此系统要能够承受恶劣环境,特别是对于部署在室外的摄像头,要能够随着时间进行更新。尤其是在电池供电时,后一点非常重要,因为它要求设计人员确保在设计中留有足够的裕量,以便在功能增加时能够实现更高的处理要求,同时仍然保证低功耗。
AI加速的重要性在于,其处理能力的要求正从传统的CPU和FPGA转移到GPU和VPU,或者所有以上处理器的异构组合,当然这取决于应用的要求。与此同时,即使面向越来越大组数据的AI加速成为主流,CPU的关键控制功能仍将保持不变。
 最前沿的电子设计资讯
最前沿的电子设计资讯

