
Jittor的开发团队来自清华大学计算机系的图形学实验室,目前有教授2名、副教授3名、助理研究员1名、博士后4名和研究生50多名。
清华大学计算机系的图形学实验室成立于1998年3月,2007年发展成为清华大学可视媒体研究中心,2010年获批成为北京市工程技术研究中心,同年和腾讯公司合作成立清华-腾讯互联网创新技术联合实验室,并于2018年,成立北京信息科学与技术国家研究中心下的可视媒体智能计算团队。
实验室主要开展计算机图形学、计算机视觉、智能信息处理、智能机器人、系统软件等方面的基础研究,近日,计图(Jittor)团队成功完成寒武纪芯片MLU270上的移植,支持推理和训练,并复现了ResNet、Alexnet、VGG等骨干网络,其中动态图推理速度相较PyTorch平均提升了276.69倍,推理精度也得到了显著的提升。

Jittor是清华大学自主研发的框架,相比PyTorch具有更好的可移植性,在保证易用的同时,能更充分发挥寒武纪芯片的性能,此次合作有望革新现有软硬件体系架构,进一步突破AI算力瓶颈,加速AI研究的创新创造,为国内的人工智能生态打下坚实基础。
Jittor团队在寒武纪芯片上与PyTorch对比了多种backbone网络模型的速度,包括alexnet、vgg系列、resnet系列在内的16个网络。
可视化结果如图1所示,动态图性能(逐层),Jittor的速度可以达到PyTorch的153~464倍,平均速度达到了PyTorch的276.69倍。其中最快的是alexnet,性能提升可达464.43倍。
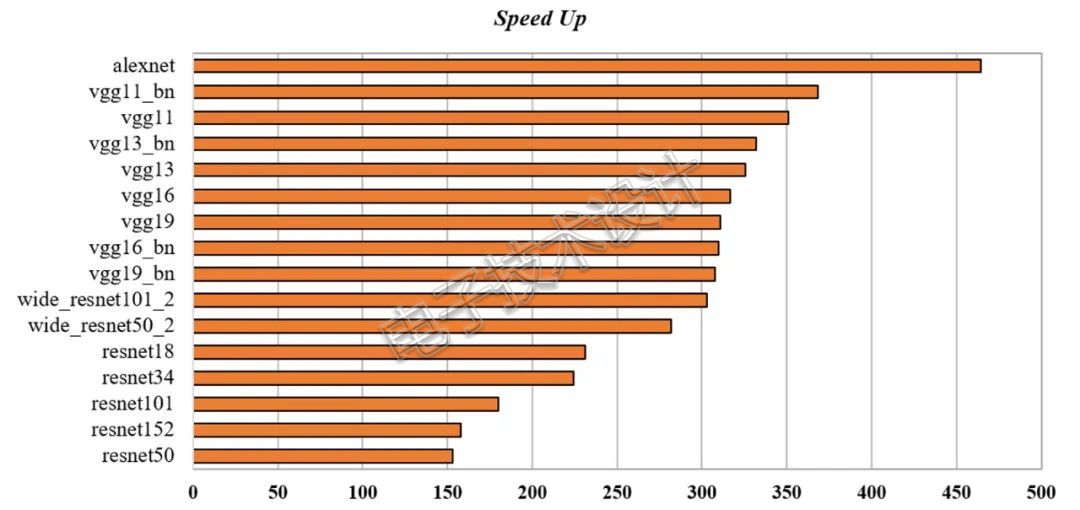 图1 不同backbone网络Jittor动态图加速比
图1 不同backbone网络Jittor动态图加速比
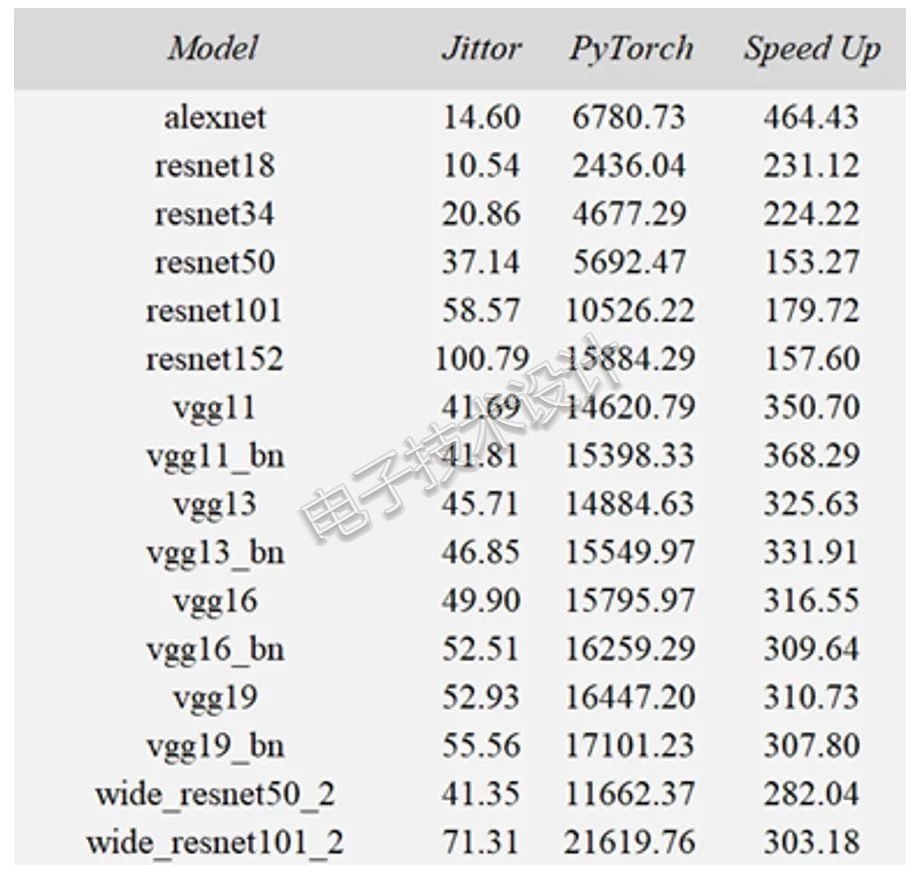
每个模型的具体数值如表1所示,其中Model一列展示了不同backbone模型,测试使用长宽均为224的rgb图像作为输入。Jittor和PyTorch两列分别展示了两个框架单次前向所需的时间,单位是毫秒。Speed Up展示了Jittor动态图的加速比。
表1 Jittor和PyTorch在不同backbone的动态图速度指标
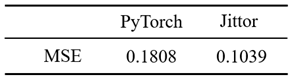
同时发现Jittor的精度损失也会比PyTorch大幅减少。以Resent18网络为例,对比了Jittor和PyTorch的MSE,结果如表2所示。对比的baseline是cpu,测试表明,Jittor的精度损失比PyTorch少42.53%。表2 resnet18的mse误差对比
主流的TensorFlow和PyTorch框架有几百甚至上千个算子,这就导致了在移植新的硬件时需要付出巨大的工作量一一复现这些算子。
而Jittor采用元算子的的概念,将神经网络所需的基本算子定义为三类共18个元算子,这些元算子能相互融合成大部分常用的算子[1]。因此对少量元算子进行优化,就能使得不同的常用算子性能都得到显著提升。
除此之外,元算子还是反向传播闭包,这意味着所有元算子的反向传播算子仍然是元算子,也就是当完成移植元算子的移植后,Jittor就天然支持训练。
因此,得益于元算子设计,在完成三类元算子的移植后,Jittor就支持了大部分常用算子的推理和简单训练(见图2)。
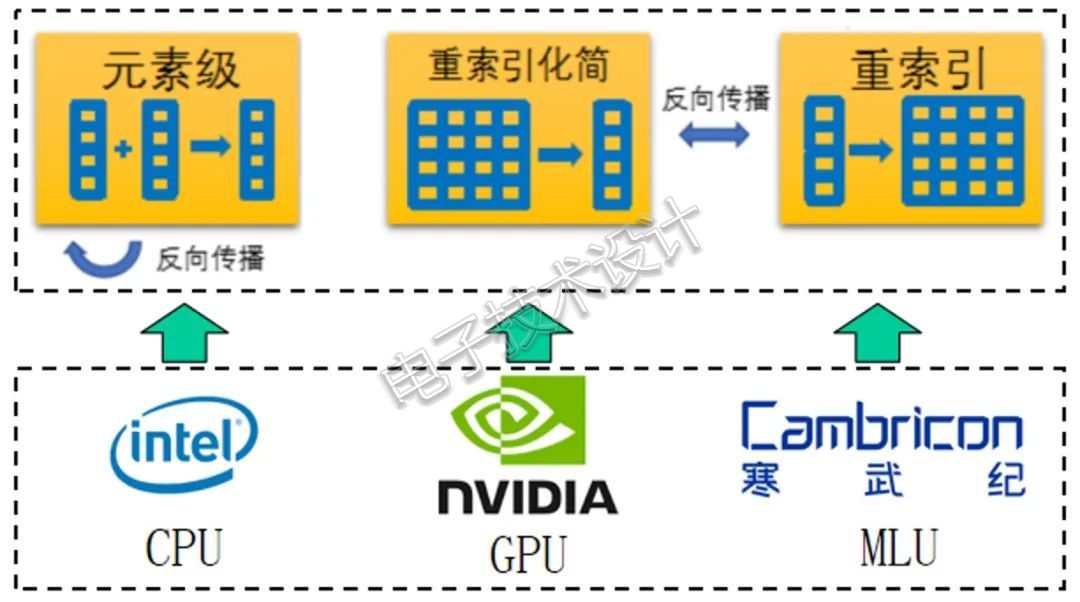
图2 在不同硬件移植元算子以支持推理和训练Jittor的多个元算子之间可以相互融合成更加复杂的算子,这些复杂算子构成了神经网络计算的多个模块,如卷积层,归一化层等(见图3)。这种融合我们称之为元算子融合,可以提升性能,节省资源。
传统的算子融合方式需要手工编写融合规则,并逐一开发融合后的算子。而Jittor通过实时分析计算图结构,自动将可以融合的元算子进行融合,从而大幅减少访存带来的开销,并减少开发工作量。
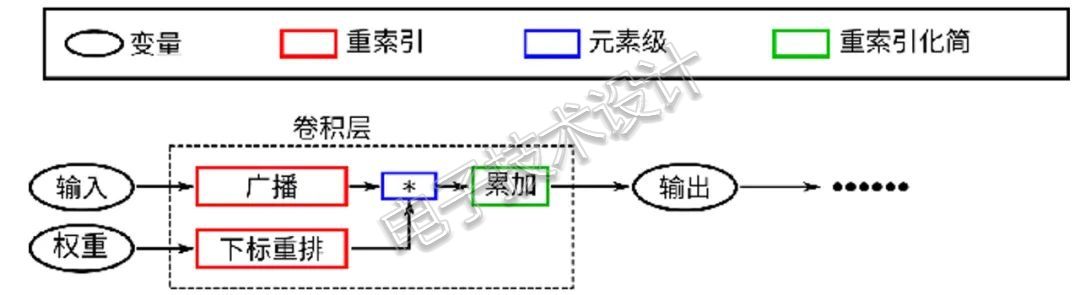 图3 使用元算子实现卷积层的方法示意图Jittor内置了元算子编译器,可以通过动态编译的方式将用户的Python代码编译成高性能的寒武纪BANG代码。
图3 使用元算子实现卷积层的方法示意图Jittor内置了元算子编译器,可以通过动态编译的方式将用户的Python代码编译成高性能的寒武纪BANG代码。
Jittor的动态编译过程相比较传统的静态编译,可以在运行时获得更多的额外信息,如计算图上下文,形状信息等等,这些信息都可以进一步用于提升算子性能。
此外,Jittor还内置了优化编译遍(complier pass),这些编译遍会根据硬件设备,自动对BANG代码进一步优化,生成对计算设备友好的底层算子。
下方这行代码为BatchNorm算子的代码节选,该代码由若干个元算子组成,仅仅一行Python就可以表达BatchNorm算子的核心思想。
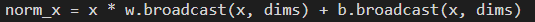
上述的Python代码将会被Jittor的元算子编译器自动优化,生成如下代码(见图4),如下代码对计算设备更加友好,使用到了BANG语言的内置函数如__bang_add进行加速。
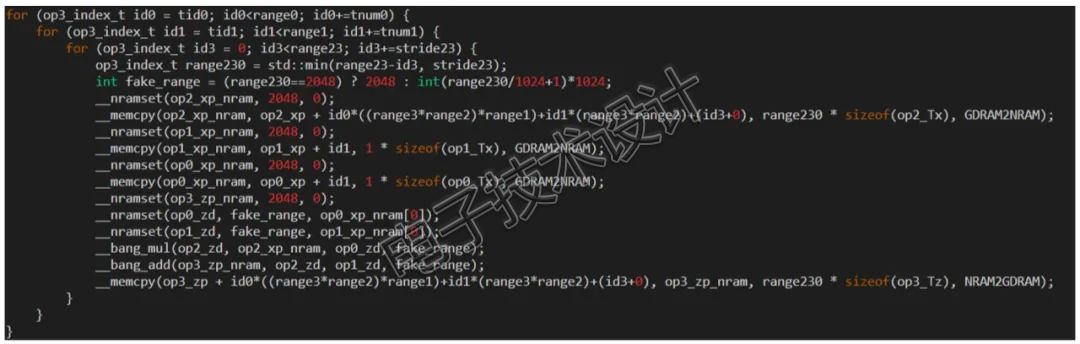
图4 Jittor动态编译生成的BANG语言代码
BANG语言由寒武纪编译器团队提出,该语言包含了全套的工具链如cncc、cngdb,大大简化了Jittor元算子的迁移成本,元算子编译器可自动生成的BANG算子。
BANG语言设计成熟,一方面,BANG语言提供了类似于CUDA语言的线程调度模式,上手简单,易于调试;另一方面又提供了内置函数,获得更好的芯片性能,完全释放芯片算力。
这套工具链可以很好地与Jittor的动态编译器整合在一起,实现动态的算子优化与注册,Jittor的元算子还可以进一步降低在寒武纪上开发自定义算子的难度。
Jittor框架带来的另一个重大提升是,保证用户在使用动态图易用的前提下,仍然可以获得显著的性能提升(见图5)。以往用户在使用PyTorch加速时,往往需要通过tracing等机制,将动态图静态化,才能够获得性能提升,然而tracing机制会降低模型的易用性。而Jittor框架在动态模式下的性能可以媲美甚至超过静态图,同时不依赖tracing机制,保证了框架的易用性。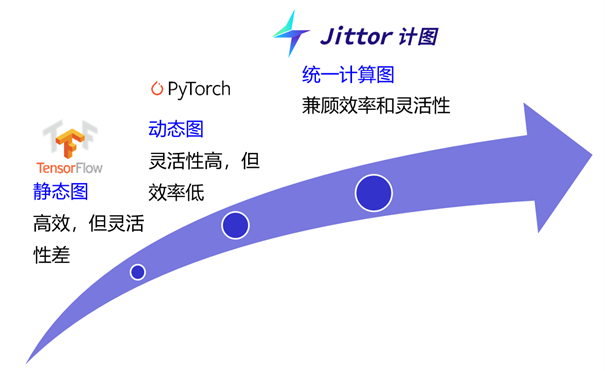
图5 统一计算图兼顾效率与灵活性
人工智能技术将作为第四次革命,带领人类走向智能时代,人工智能的快速发展既离不开算力的突破和算法的创新,更依赖于深度学习框架和AI芯片。
Jittor作为清华大学发布的自主可控的深度学习框架,秉承着开源开放,厚德载物的精神,支持国产芯片的发展。本次Jittor实现对寒武纪的成功支持,不仅实现了基础骨干网络的推理与训练,并且相比较国际主流框架PyTorch,获得了显著的性能提升,同时具有动态图的易用性,让学术界和工业界的用户都能更容易上手。
未来Jittor框架将针对更多不同类型的应用、不同的场景、训练以及推理进行更加深度的优化,提供更多易于上手,开箱即用的开源工具包,贡献开源社区,支持更多国产芯片,推动国产AI生态的快速发展。
参考文献
Shi-Min Hu, Dun Liang, Guo-Ye Yang, Guo-Wei Yang, Wen-Yang Zhou, Jittor: a novel deep learning framework with meta-operators and unified graph execution, Science China Information Science,2020, Vol. 63, No. 12, article no. 222103, pages: 1-21.
责编:胡安
 最前沿的电子设计资讯
最前沿的电子设计资讯
