
五月中旬,中国商飞公司的C919大飞机从浦东机场起飞,标志着国产大飞机C919正式开启商用之路。五月下旬,有报道曝光C919的座舱显示系统采用HKM9000 GPU图形处理器,已经实现了完全的国产化。这款航电GPU采用了完全自主的指令架构、核心算法、图形流水、软硬件代码及生态,本文就GPU的架构及其研发难度进行重点介绍。


HKM9000 GPU图形处理器由航空工业计算所翔腾微电子公司从2014年开始研发,历时6年,于2020年4月研制成功。这也是国内第一款应用到民航领域的专用GPU芯片。
从多年前就流行的游戏,到最近几年在比特币等数字货币的挖矿等盛行的领域,主要的核心硬件就是GPU显卡(后来挖矿采用了其他更简洁的方案)。
也许有人认为GPU比较简单,不会比CPU复杂。然而,在GPU领域,目前英伟达(NVIDIA)是当之无愧的龙头老大,桌面和移动端CPU处理器领域的英特尔、AMD等公司的GPU技术和产品都与英伟达有相当大的差距。
虽然GPU与CPU并不能一定说谁的技术难度更大,但GPU的研发难度无疑也是非常大的,在某种情况下比CPU更难,这种难度首先就体现在架构上,因为现在发展的GPU架构已经在主要的几大公司中形成了专利壁垒。
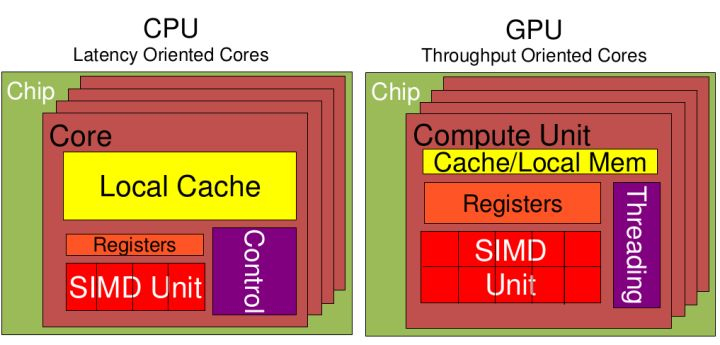
通用的CPU是SISD架构,而GPU架构是SIMD。
从平面角度看是:
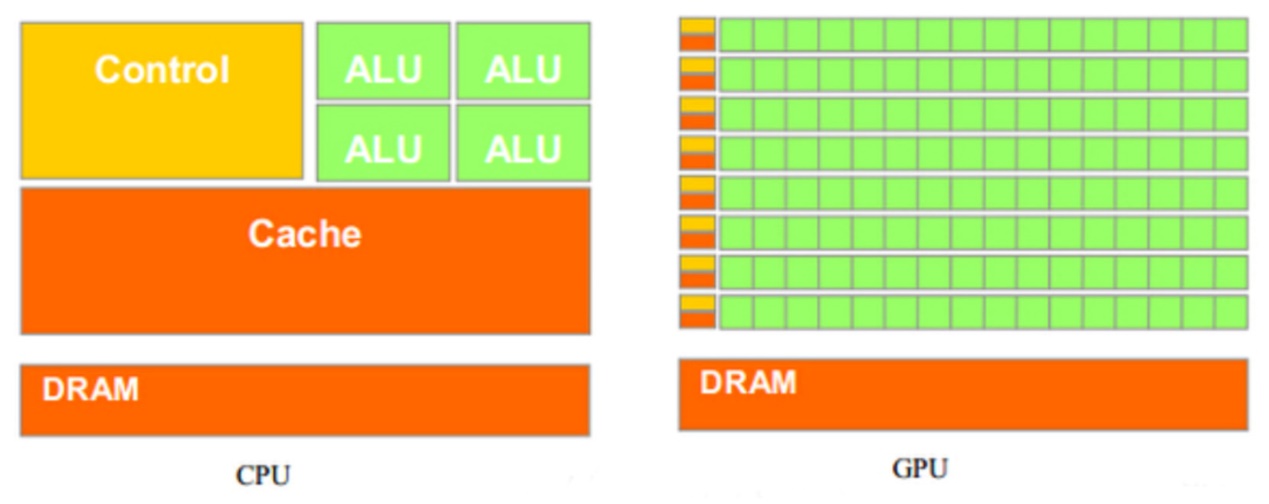
SISD机器是一种传统的串行计算机,它的硬件不支持任何形式的并行计算,所有的指令都是串行执行。并且在某个时钟周期内,CPU只能处理一个数据流。因此这种机器被称作单指令流单数据流机器。早期的计算机都是SISD机器,如冯诺.依曼架构,如IBM PC机,早期的巨型机和许多8位的家用机等。
SIMD是采用一个指令流处理多个数据流。这类机器在数字信号处理、图像处理、以及多媒体信息处理等领域非常有效。GPU就是这样的架构。
GPU架构就是围绕一个流式多处理器(SM)的扩展阵列搭建的。通过复制这种结构来实现GPU的硬件并行。包含了关键组件:
Fermi架构是第一个完整的GPU架构,这是英伟达(NVIDIA)公司于2010年推出的架构。

来源:NVIDIA Fermi架构文档
Fermi逻辑架构中包含具体数据如下:
SM包括下面这些资源:
每个多处理器SM有16个加载/存储单元所以每个时钟周期内有16个线程(半个线程束)计算源地址和目的地址。
特殊功能单元SFU执行固有指令,如正弦,余弦,平方根和插值,SFU在每个时钟周期内的每个线程上执行一个固有指令。
每个SM有两个线程束调度器,和两个指令调度单元,当一个线程块被指定给一个SM时,线程块内的所有线程被分成线程束,两个线程束选择其中两个线程束,在用指令调度器存储两个线程束要执行的指令。
NVIDIA还有其他架构,面向超强弹性数据中心核心的AMPERE 架构(7nm),面向AI的HOPPER 架构(4N 工艺),专业图形应用中的Turing架构,人工智能引擎VOLTA架构。
此外,先前还有Pascal 架构(16nm),Kepler架构,Maxwell架构。
Intel以往是没有独立的GPU的,我们以往常见的是Intel CPU中集成了显卡,称之为集显。直到2021年8月,Intel宣布推出面向游戏玩家的Xe-HPG架构Alchemist GPU;以及面向数据中心的Xe-HPC架构GPU芯片Ponte Vecchio。2022年3月,Intel正式发布了Intel Arc A系列移动端独立显卡。
最近,AMD透露了下一代GPU架构Polaris,这是 Graphics Core Next (GCN)架构的第四代,目前AMD显卡如 Radeon R9 285和R9 Fury 使用的是 GCN 1.2架构。新架构显卡最引入瞩目之处是使用14纳米FinFET工艺。
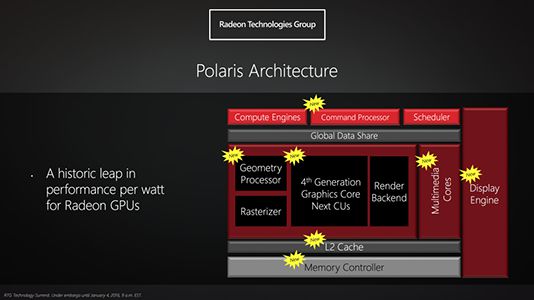
过去几年AMD及其竞争对手 Nvidia的显卡一直停留在28纳米工艺上,采用14纳米工艺将能大幅改进功耗和每瓦性能。Polaris还将改进命令处理器,几何图形处理器、L2缓存、内存控制器、多媒体核心、显示引擎、支持4K@60FPS h.265硬编码解码, DisplayPort 1.3和HDMI 2.0a等新技术。
暂时未有公开报道国产HKM9000 GPU的架构。但据中国航空新闻网的报道,HKM9000 GPU芯片具有完全自主的指令架构、核心算法、图形流水、软硬件代码及生态。并且面向典型机载座舱显示进行了应用级、算法级、架构级、电路级、软件级等系列优化。构建了模型驱动的芯片敏捷设计开发流程,建设了完备的应用开发生态体系。
目前HKM9000已成功适配国内外10余款处理器及天脉全系列、VxWorks、翼辉、Linux等操作系统,实现了VAPS、iDATA、SCADE、Qt、MiniGUI、FreeType等图形应用开发软件,在航空、航天、兵器等领域13家用户、18种显控产品中得到应用,功能稳定、可靠。
根据实测,HKM9000相比商业级芯片性能普遍提升20%,在仪表盘等场景中性能提升可达2-3倍。
从头开始研发GPU主要有两大困难。第一是专利壁垒,第二是GPU芯片的架构体系化创新。
在专利壁垒方面,GPU作为先进工艺的数字芯片,高技术含量IP的持续演进是技术自主和市场竞争优势的保障。在该领域起步早的全球GPU巨头们已筑建了层层专利保护墙。以GPU架构IP专利为例,苹果在该领域也绕不开专利授权:从A4到A10X的所有苹果手机处理器中的GPU都是采用Imagination的IP,A10之后苹果通过架构授权,有了自己的GPU架构把控,依然是基于Imagination的TBDR架构专利授权,隶属于该架构分支。但一旦架构授权后独立演进了,也就不再被专利卡脖子了。
在GPU芯片设计方面,GPU也绝非简单的芯片设计,其设计较一般芯片更复杂,系统更庞大,涉及面更广。做GPU需要极其专业的团队,团队从前到后要做到软硬件全栈设计开发。专业人才要涵盖架构、算法、硬件、软件以及各种验证方式,包括后端、版图、驱动、测试、结构、生产代工等,大批量还需考虑供应链等领域。这点从国产GPU HKM9000的研发单位航空工业计算所翔腾微电子申请的专利中可见一斑(见后面的详解)。
而作为航空领域的专用GPU,其设计则需要考虑得更多,在上万米高空上极寒高热的应用环境下的稳定性,数据传输的稳定性,严苛的可靠性,以及极端情况下依然能够工作的要求等都对专用GPU提出了更多工艺制造和电气特性方面的更高要求。
航空领域的标准远远高于普通消费级和工业级产品的标准,航电专用GPU产品标准与军用方面的标准已经很接近了。
航电系统GPU特点
为了保证飞机完成预定任务,达到各项规定性能,飞机的综合航空电子系统(简称航电系统)采用分布式计算机结构,通过多路传输数据总线将多种机载电子设备(分系统)交联在一起。航电系统的GPU被称为航电仪表,是独立的电子仪表系统(Electronic Instrument System,EIS),可以为飞行人员提供飞行器及其分系统信息,显示飞机某部分的姿态、高度或运行状况的设备,有着综合显示各种信息、易于追加资料等特点。
早期飞行器的航电系统采用机械化的方式对飞行器的运行参数进行收集,并传递到飞行员的座舱进行显示。机械连杆、液压等传动装置,会将飞行器对空速度、对地速度表,水平仪、高度仪等传感器的信息反馈至座舱的机械化指针仪表盘。
 意大利沃兰迪亚博物馆中的梅塞施密特Bf.109E“埃米尔”战斗机仪表盘。该机配备了全新的戴姆勒-奔驰DB 601发动机,发动机采用了燃油喷射系统和涡轮增压器,于1939年初成为德军装备。
意大利沃兰迪亚博物馆中的梅塞施密特Bf.109E“埃米尔”战斗机仪表盘。该机配备了全新的戴姆勒-奔驰DB 601发动机,发动机采用了燃油喷射系统和涡轮增压器,于1939年初成为德军装备。
现代EIS用电子数据采集取代了传统的机械采集。
EIS采用了先进的电子化传感器。电子化传感器可以高速采集真实环境中的物理模拟信号,通过高性能信号处理系统,对其进行信号滤波、放大等操作,得到高信噪比的数字信号,随后通过超高带宽的信号传输总线,将有效的飞行器运行关键参数信息传递给座舱的高性能GPU绘图显示系统,飞行员便能通过智能液晶仪表盘,得到图形化的信息显示。
笔者Challey从HKM9000 GPU的研发单位航空工业计算所翔腾微电子公司的专利申请情况看到有120多个专利,绝大部分都是有关GPU方面的。
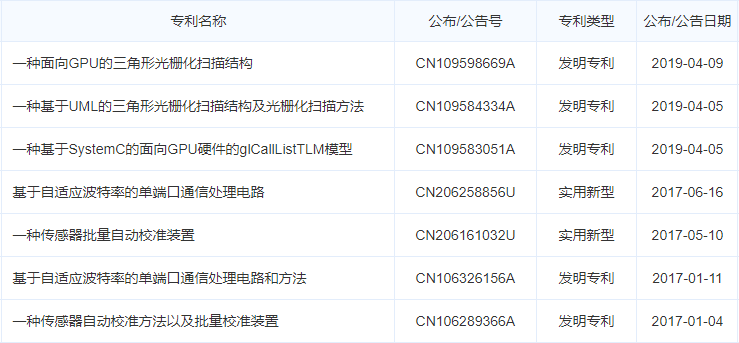
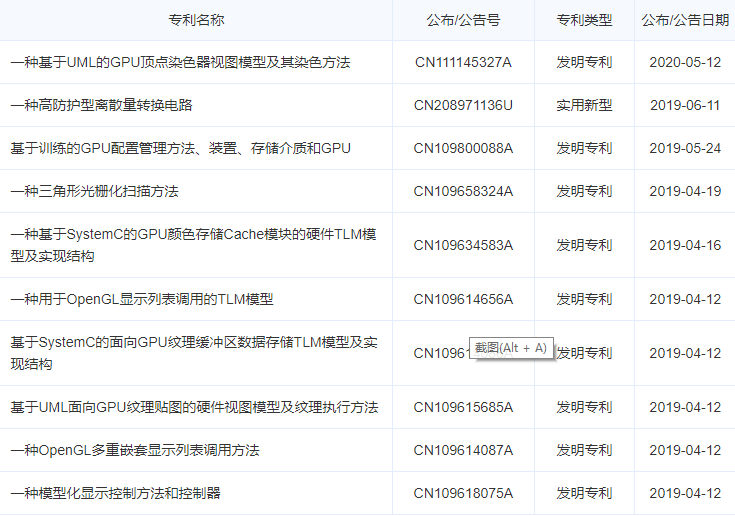
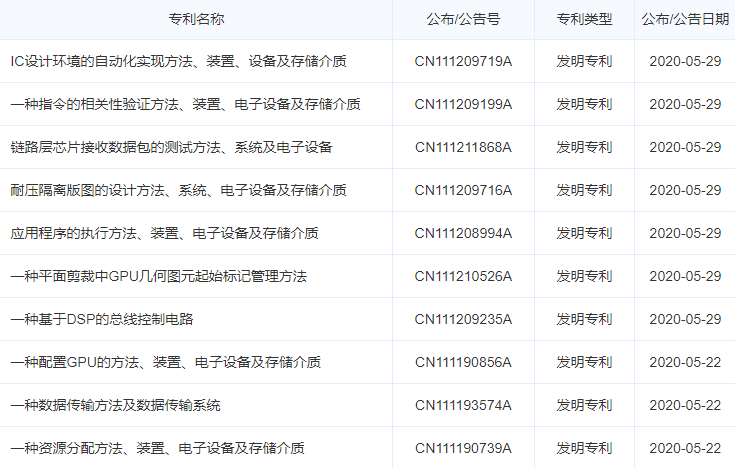
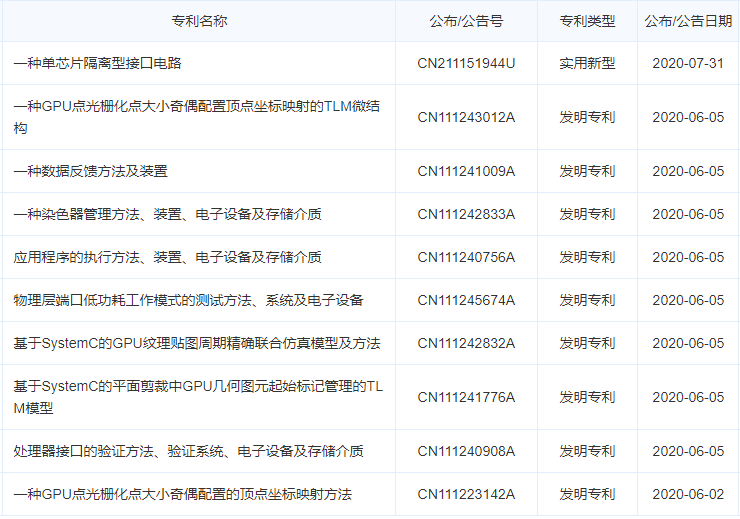
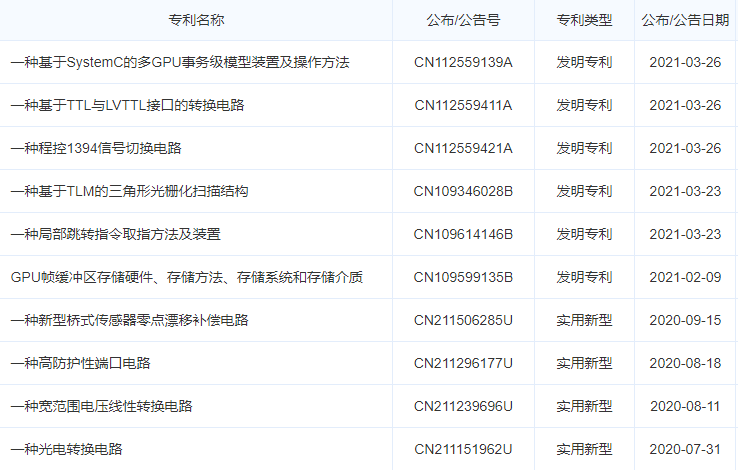
这些专利包含了:
三角形光栅化扫描方法,基于UML的GPU顶点染色器视图模型及其染色方法,基于训练的GPU配置管理方法、装置、存储介质和GPU,基于SystemC的GPU颜色存储Cache模块的硬件TLM模型及实现结构,基于SystemC的面向GPU纹理缓冲区数据存储TLM模型及实现结构,基于SystemC的GPU纹理贴图周期精确联合仿真模型及方法,基于SystemC的平面剪裁中GPU几何图元起始标记管理的TLM模型,用于OpenGL显示列表调用的TLM模型, 基于UML面向GPU纹理贴图的硬件视图模型及纹理执行方法,OpenGL多重嵌套显示列表调用方法,模型化显示控制方法和控制器,配置GPU的方法、装置、电子设备及存储介质,基于DSP的总线控制电路,平面剪裁中GPU几何图元起始标记管理方法, GPU点光栅化点大小奇偶配置的顶点坐标映射方法等等。
其中面向GPU的三角形光栅化扫描结构,涉及面向GPU的三角形光栅化扫描结构,包括:初始化单元,连接所述数据获取单元,用于接收三角形数据信息,并根据所述三角形数据信息获取X轴起始坐标、Y轴检测范围;Y轴步进单元,连接所述初始化单元,用于对X轴进行使能标识,并根据所述Y轴检测范围控制检测元素沿第一方向的步进;若干X轴扫描单元,分别连接所述Y轴步进单元,用于根据所述X轴的使能标识和所述X轴起始坐标控制所述检测元素沿X轴的扫描。本发明提供的一种面向GPU的三角形光栅化扫描结构,集成有初始化单元、Y轴步进单元和X轴扫描单元,实现了GPU的三角形光栅化扫描,从而实现了从系统架构文档到RTL的转换。
基于SystemC的面向GPU硬件的glCallListTLM模型,涉及基于SystemC的面向GPU硬件的glCallListTLM模型,包括:显示列表存储单元、DMA控制单元、CallListFIFO缓冲单元、调用控制单元和嵌套表单元;其中,显示列表存储单元用于存储显示列表信息;调用控制单元用于对输入命令或嵌套表信息进行处理,获取描述符指令;DMA控制单元用于根据描述符指令提取预定显示列表信息,并进行搬运;CallListFIFO缓冲单元用于对搬运的预定显示列表信息进行缓存;调用控制单元还用于对缓存的预定显示列表信息进行处理,获得处理信息;嵌套表单元用于根据处理信息得到嵌套表信息。提供的基于SystemC的面向GPU硬件的glCallListTLM模型采用SystemC建模语言,可以摆脱传统信号级别的硬件描述,使用丰富的数据结构进行硬件的高层次行为、时序的抽象。
基于UML的三角形光栅化扫描结构及光栅化扫描方法,涉及一种基于UML的三角形光栅化扫描结构及光栅化扫描方法,包括:数据获取模块,用于获取三角形数据信息;三角形扫描模块,用于根据三角形数据信息对三角形进行扫描,并根据扫描结果获取有效坐标数据;三角形光栅化模块,用于根据有效坐标数据对扫描后的三角形进行光栅化。本发明提供的基于UML的三角形光栅化扫描结构,集成有数据获取单元、三角形扫描模块和三角形光栅化模块,数据获取单元、三角形扫描模块和三角形光栅化模块之间的数据传输通过UML的端口实现,使得X轴扫描与Y轴步进能够并行执行,降低了三角形光栅化的复杂度,改善了三角形光栅化扫描结构的扫描性能和速度。
GPU硬件结构精密复杂,是长期技术演进的结果。高级图形处理步骤较多,包括顶点处理、光栅化、纹理贴图等步骤,给予支持的是底层精密复杂的硬件结构。从英伟达2010年正式推出第一个完整的GPU计算架构Fermi以来,已经迭代5次,每一次都是对硬件的升级与改进。
而且,英伟达针对不同的领域、不同的应用场景推出了不同的GPU架构。
同时,算法与生态是GPU的软实力。GPU图形渲染需要用到计算图形学,计算图形学是一门复杂的学科,涉及数学、物理等多种知识。模拟真实世界是十分困难的,树叶抖动、头发丝被风吹起、水波荡漾这样看似平常的场景,在计算机上实现的背后是大量的图形算法。软件生态是GPU厂商的重要竞争屏障。一方面,英伟达与行业伙伴形成商业合作或者互相授权;另一方面,英伟达推出供软件开发人员使用的CUDA平台,形成开发人员社区生态,截至2020年,CUDA已经成为全球高级图形处理和AI计算的权威,使英伟达成为全球GPU龙头。
算法上,图形处理算法涉及模拟真实物理世界,需要考虑物理、数学等多种问题。GPU比FPGA和ASIC技术更难。功能上,GPU兼具图形显示与AI计算,性能更强。算力上,GPU内核算力更强,GPU做图形渲染需要双浮点精度,而仅用于AI计算的FPGA和ASIC最多只需要单浮点精度。
Intel早在1997年就曾研发GPU,当时通过收购C&T获得2D显示核心技术,3D技术源于拥有20%股权的Real3D。1998年,依靠Real3D的技术,Intel推出了第一款独立GPU i740,但后来因为研发结果不理想等原因,未再继续研发独立GPU。
2007年,看到英伟达开启GPGPU战略、推出CUDA,英特尔为保持优势,计划重新推出独立GPU产品Larrabee,但由于研发进度不及预期、性能不佳等原因,Intel于2010年5月宣布取消独立GPU研发计划。
Intel二十多年多次研发GPU,屡屡未能成功。
直到2021年8月,Intel宣布推出面向游戏玩家的Xe-HPG架构Alchemist GPU;以及面向数据中心的Xe-HPC架构GPU芯片Ponte Vecchio。
2022年3月,Intel才正式发布了Intel Arc A系列移动端独立显卡。
更多关于CPU/GPU等芯片技术的讨论可以关注我们或者联系作者(微信同名)。
GPU设计是一项系统工程,不仅仅包含硬件架构,还包括算法和软件生态等多个方面,缺一不可。相对FPGA和ASIC,不论是从功能上,还是硬件上,GPU设计难度都更高。
HKM9000 GPU图形处理器已经顺利通过民用大飞机C919座舱显控系统的联试验证,转入适航认证阶段。中国国产大飞机C919也预计在2023年首批交付、2025年量产50架。
除了专用航空领域研发HKM9000 GPU的翔腾微电子,当前,中国商用市场也出现了景嘉微、芯动科技、壁仞科技、摩尔线程和沐曦等GPU公司。
期望国产GPU不仅仅在设计和应用上创新,更在GPU底层架构上出现更多的自主突破。
中国航空新闻网;
NVIDIA官方文档(需要GPU架构资料的可联系我们或者作者);
武汉大学计算机学院智能计算系统实验室:
https://blog.csdn.net/weixin_51971301/article/details/124703677
迪捷软件:
https://blog.csdn.net/digi2020/article/details/124377351
 最前沿的电子设计资讯
最前沿的电子设计资讯

