
现在,特斯拉不仅是个汽车公司、AI公司,还是个芯片公司。在AI训练芯片界,用于训练AI模型的芯片供应商,除了英特尔、英伟达和Graphcore,现在还有特斯拉。
近日特斯拉亮相的D1 芯片宣称拥有500亿个晶体管,超过了AMD拥有395.4亿个晶体管的Epyc Rome,落后于NVIDIA的GA100 Ampere SoC的540亿个晶体管的记录。
D1 芯片总共有645mm²,每mm²上集成7750万个晶体管的有效晶体管密度,仅次于移动芯片苹果M1,功率密度高于Nvidia A100 GPU。
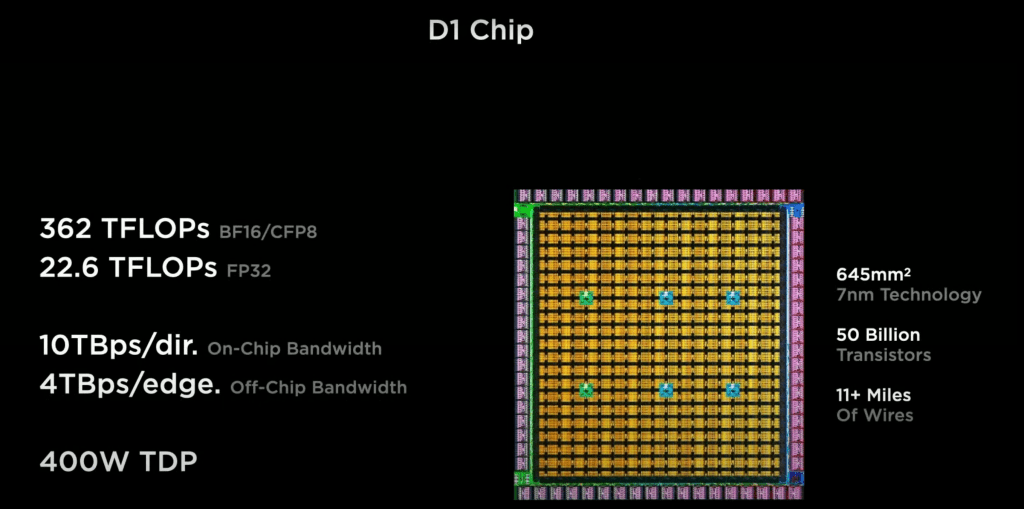
D1使用 7nm工艺,推测是由三星或台积电代工,考虑到三星也制造了特斯拉的HW3芯片,所以前者代工D1的可能性更大一些。
25个D1芯片组成一个Training Tile(训练片,EDN没有看到官方翻译,根据Tile的原意”瓦片”和它的外观暂且译为”训练片”吧);然后12个训练片可以组成一个服务器机柜,共108 PFlops;几个机柜再组成Dojo超级计算机。

图:每个服务器机柜超过 100,000 个功能单元、400,000 个定制内核和132GB SRAM。
特斯拉曾经采用NVIDIA GPU构建的超级计算机上过Top10榜单,性能仅略低于中国的太湖之光:

从排名上看起来Dojo并不是计算能力最强的超级计算机,这是Dojo的设计目的只是针对一项非常具体的任务,即:基于大量360度视频训练神经网络。所有代码都是专门为在此硬件上理想工作而编写的。
相比之下,其他超级计算机的构建都考虑到了灵活性,以便能够适应大量不同的任务。当然,如果真的要在视频训练上一决高下,即使是最强大的 Fugaku (富岳),也很可能是比Dojo慢的。
何况巨大的Fugaku是由256 个机柜组成,Dojo仅由10个机柜组成,因此在尺寸方面Dojo也是最小的超级计算机。
如果特斯拉在Dojo中增加54个机柜,Dojo就能超过Fugaku。
智能手机和特斯拉的HW3都是有SoC之外的RAM 芯片的。即使是最快的最厉害的硬盘驱动器也做不到和RAM一样的随机存取,无法取代RAM。
理论上,最新的PCIe 4技术只能达到0.5~3GB/s,比消费类计算机标准DDR4 RAM的20~25GB/s差太多,更别提高达50GB/s的下一代 DDR5 RAM。
智能手机和消费电脑通常使用 4-32GB的RAM,专业工作站的RAM甚至可以达到512GB。
那么,如果特斯拉的训练芯片没用RAM,那用的是啥?
它内部是有一个更快的随机内存层,称为缓存。当 SoC/CPU 调用DRAM时,响应时间约为 60纳秒;而L3缓存或片上 SRAM 的响应时间可低至10纳秒。
英特尔目前最大的L3缓存是57MB,IBM的记录是120MB,AMD最强大的处理器有256MB的L3缓存,而特斯拉在 2019 年宣布的 HW3 芯片有 64 MB 的 SRAM。
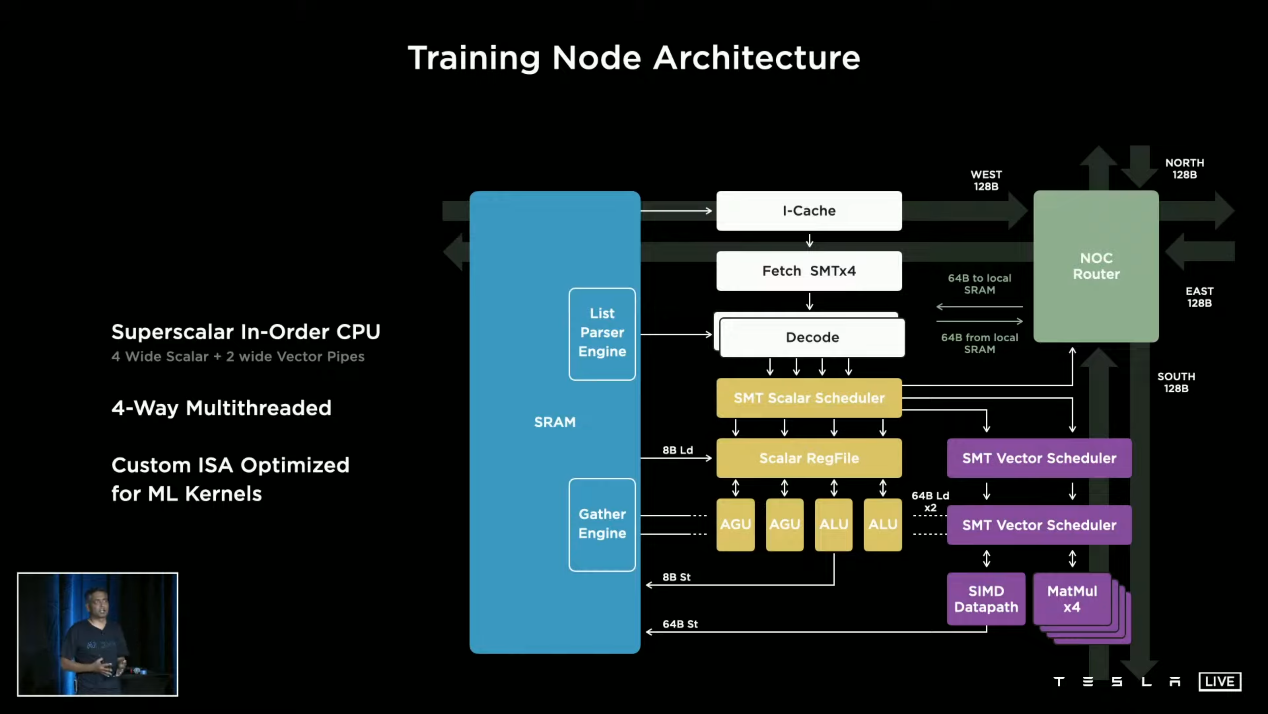
特斯拉的训练节点带有1.25MB的SRAM,354个节点组成的计算阵列,也就是这个SoC算下来就是424.8 MB的缓存,这超过了所有其他处理器。——这有可能都不是L3缓存,而是更快的 L2了。
通常SoC是通过引脚把信号发送到主板上再进行传输,但特斯拉并没有把SoC从晶圆上割下来,而是把留在一片晶圆上的所有SoC连接起来。
新 PCI-e Gen 4 连接的最新 SSD 的理论限制为 64 GB/s,特斯拉的每个连接器能达到900 GB/s的速度,推测是他们定制了自己的连接方式。

每个 D1 芯片的功耗仅400 W,25个芯片组成的MCM训练片的功耗为15千瓦。训练片是液体冷却的,据说用了10公斤液体,但特斯拉没说是水冷。 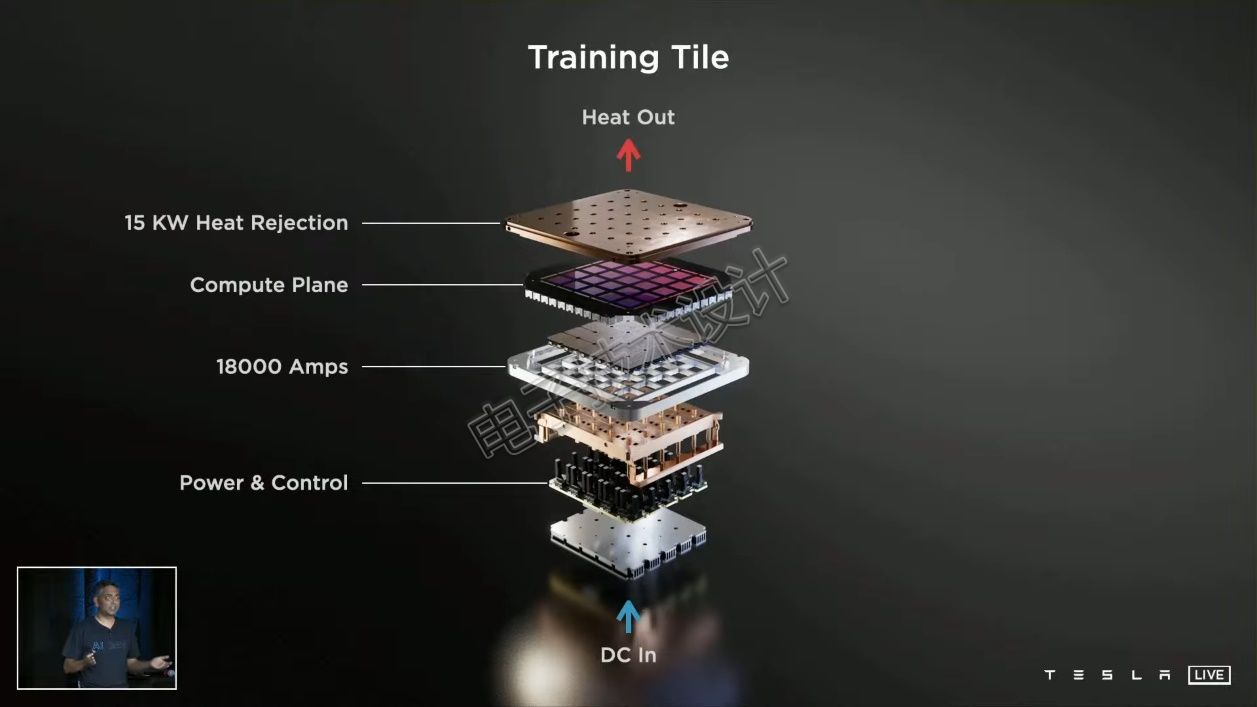
在Tesla的训练片中,有SoC的一侧与常规处理器一样是暴露着的,可以直接冷却。另一侧被稳压器盖住了,如上图所示。
那么稳压器直接盖在处理器有啥好处?
常见的处理器的电源都是装在处理器旁边的主板上,电流需要通过主板、插座、引脚和SoC;而Dojo训练片的电源可以直接传输到SoC,减少了散发的热量。
最后,看起来特斯拉现在已经掌握着摩尔定律的衣钵,马斯克表示,“We should have Dojo operational next year”。明年值得期待。
 最前沿的电子设计资讯
最前沿的电子设计资讯
