
整体而言,语音情感识别研究在该时期仍旧处于初级阶段, 主要侧重于情感的声学特征分析这一方面,作为研究对象的情感语音样本也多表现为规模小、自然度低、语义简单等特点,虽然有相当数量的有价值的研究成果相继发表,但是并没有形成一套被广泛认可的、系统的理论和研究方法。进入 21 世纪以来,随着计算机多媒体信息处理技术等研究领域的出现以及人工智能领域的快速发展,语音情感识别研究被赋予了更多的迫切要求,发展步伐逐步加快。 2000 年,在爱尔兰召开的 ISCA Workshop on Speech and Emotion 国际会议首次把致力于情感和语音研究的学者聚集在一起。近 10 余年来,语音情感识别研究工作在情感描述模型的引入、情感语音库的构建、情感特征分析等领域的各个方面都得到了发展。 下面将从语音情感数据库的采集、语音情感标注以及情感声学特征分析方面介绍语音情感计算。
1、语音情感数据库的采集
语音情感识别研究的开展离不开情感语音数据库的支撑。情感语音库的质量高低,直接决定了由它训练得到的情感识别系统的性能好坏。评价一个语音情感数据库好坏的一个重要标准是数据库中语音情感是否具备真实的表露性和自发性。目前,依据语音情感激发类型的不同,语音情感数据库可分为表演型、诱发型和自发型三种。
具体来说,表演型情感数据库通过专业演员的表演,把不同情感表达出来。在语音情感识别研究初期,这一采集标准被认为是研究语音情感识别比较可靠的数据来源,因为专业演员在
表达情感时,可以通过专业表达获得人所共知的情感特征。比如,愤怒情感的语音一般会具有很大的幅值和强度,而悲伤情感的语音则反之。由于这一类型的数据库具有表演的性质,情感的表达会比真实情感夸大一点,因此情感不具有自发的特点。依据该类型数据库来学习的语音情感识别算法,不一定能有效应用于真实生活场景中。第二种称之为诱发型情感数据库。被试者处于某一特定的环境,如实验室中,通过观看电影或进行计算机游戏等方式,诱发被试者的某种情感。目前大部分的情感数据库都是基于诱发的方式建立的。诱发型情感数据库产生的情感方式相较于表演型情感数据库,其情感特征更具有真实性。最后一种类型属于完全自发的语音情感数据库,其语料采集于电话会议、电影或者电话的视频片段,或者广播中的新闻片段等等。由于这种类型的语音情感数据最具有完全的真实性和自发性,应该说最适合用于实用的语音情感识别。但是,由于这些语音数据涉及道德和版权因素,妨碍了它在实际语音情感识别中的应用。
2、语音情感数据库的标注
对于采集好的语音情感库,为了进行语音情感识别算法研究,还需要对情感语料进行标注。标注方法有两种类型:
离散型情感标注法指的是标注为如生气、高兴、悲伤、害怕、惊奇、讨厌和中性等,这种标注的依据是心理学的基本情感理论。基本情感论认为,人复杂的情感是由若干种有限的基本情感构成的,就像我们自古就有“喜、怒、哀、乐,恐、悲、 惊” 七情的说法。 不同的心理学家对基本情感有不同的定义,由此可见,在心理学领域对基本情感类别的定义还没有一个统一的结论,因此不同的语音情感数据库包含的情感类别也不尽相同。这不利于在不同的语音情感数据库上,对同一语音情感识别算法的性能进行评价。此外,众所周知,实际生活中情感的类别远远不止有限几类。基于离散型情感标注法的语音情感识别容易满足多数场合的需要,但无法处理人类情感表达具有连续性和动态变化性的情况。在实际生活中,普遍存在着情感变化的语音,比如前半句包含了某一种情感,而后半句却包含了另外一种情感,甚至可能相反。 例如,某人说话时刚开始很高兴,突然受到外界刺激,一下子就生气了。对于这种在情感表达上具有连续和动态变化的语音,采用离散型情感标注法来进行语音情感识别就不合适了。因为此时语音的情感,己不再完全属于某一种具体的情感。
维度情感空间论基于离散型情感标注法的缺陷,心理学家们又提出了维度情感空间论,即对情感的变化用连续的数值进行表示。不同研究者所定义的情感维度空间数目有所不同,如二维、三维甚至四维模型。针对语音情感,最广为接受和得到较多应用的为二维连续情感空间模型,即“激活维-效价维” (Arousal-Valence) 的维度模型。 “激活维” 反映的是说话者生理上的激励程度或者采取某种行动所作的准备,是主动的还是被动的; “效价维” 反映的是说话者对某一事物正面的或负面的评价。随着多模态情感识别算法的研究,为了更细致的地描述情感的变化,研究者在“激活维-效价维” (Arousal-Valence) 二维连续情感空间模型的基础上,引入“控制维” , 即在“激活维-效价维-控制维(Arousal-Valence/Pleasure-Power/Dominance) ”三维连续情感空间模型上对语音情感进行标注和情感计算。需要强调的是,离散型和连续型情感标注之间,它们并不是孤立的,而是可以通过一定映射进行相互转换。
3、情感声学特征分析
情感声学特征分析主要包括声学特征提取和声学特征选择、声学特征降维。采用何种有效的语音情感特征参数用于情感识别,是语音情感识别研究最关键的问题之一,因为所用的情感特征参数的优劣直接决定情感最终识别结果的好坏 。
声学特征提取。 目前经常提取的语音情感声学特征参数主要有三种:韵律特征、音质特征以及谱特征。 在早期的语音情感识别研究文献中,针对情感识别所首选的声学特征参数是韵律
特征,如基音频率、振幅、发音持续时间、语速等。这些韵律特征能够体现说话人的部分情感信息,较大程度上能区分不同的情感。因此,韵律特征已成为当前语音情感识别中使用最广泛并且必不可少的一种声学特征参数除了韵律特征,另外一种常用的声学特征参数是与发音方式相关的音质特征参数。三维情感空间模型中的“激发维”上比较接近的情感类型,如生气和高兴,仅使用韵律特征来识别是不够的。
音质特征包括共振峰、频谱能量分布、 谐波噪声比等,不仅能够很好地表达三维中的“效价维”信息,而且也能够部分反映三维中的“控制维”信息。因此,为了更好地识别情感,同时提取韵律特征和音质特征两方面的参数用于情感识别,已成为语音情感识别领域声学特征提取的一个主要方向。谱特征参数是一种能够反映语音信号的短时功率谱特性的声学特征参数, Mel 频率倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)是最具代表性的谱特征参数,被广泛应用于语音情感识别。由于谱特征参数及其导数,仅反映语音信号的短时特性,忽略了对情感识别有用的语音信号的全局动态信息。近年来,为了克服谱特征参数的这种不足之处,研究者提出了一些改进的谱特征参数,如类层次的谱特征、调制的谱特征和基于共振峰位置的加权谱特征等。
声学特征选择。 为了尽量保留对情感识别有意义的信息,研究者通常都提取了较多的与情感表达相关的不同类型的特征参数,如韵律特征、音质特征、谱特征等。 任意类型特征都有各自的侧重点和适用范围, 不同的特征之间也具有一定的互补性、相关性。此外,这些大量提取的特征参数直接构成了一个高维空间的特征向量。这种高维性质的特征空间,不仅包含冗余的特征信息,导致用于情感识别的分类器训练和测试需要付出高昂的计算代价,而且情感识别的性能也不尽如人意。因此,非常有必要对声学特征参数进行特征选择或特征降维处理,以便获取最佳的特征子集,降低分类系统的复杂性和提高情感识别的性能。
特征选择是指从一组给定的特征集中,按照某一准则选择出一组具有良好区分特性的特征子集。
特征选择方法主要有两种类型:封装式(Wrapper)和过滤式(Filter)。 Wrapper 算法是将后续采用的分类算法的结果作为特征子集评价准则的一部分,根据算法生成规则的分类精度选择特征子集。 Filter 算法是将特征选择作为一个预处理过程,直接利用数据的内在特性对选取的特征子集进行评价,独立于分类算法。
声学特征降维。 特征降维是指通过映射或变换方式将高维特征空间映射到低维特征空间,已达到降维的目的。特征降维算法分为线性和非线性两种。最具代表性的两种线性降维算法,如主成分分析 PCA(Principal Component Analysis)和线性判别分析 LDA(Linear DiscriminantAnalysis),已经被广泛用于对语音情感特征参数的线性降维处理。也就是, PCA 和 LDA 方法被用来对提取的高维情感声学特征数据进行嵌入到一个低维特征子空间,然后在这降维后的低维子空间实现情感识别,提高情感识别性能。
近年来,新发展起来的基于人类认知机理的流形学习方法比传统的线性 PCA 和 LDA 方法更能体现事物的本质,更适合于处理呈非线性流形结构的语音情感特征数据。但这些原始的流形学习方法直接应用于语音情感识别中的特征降维,所取得的性能并不令人满意。主要原因是他们都属于非监督式学习方法,没有考虑对分类有帮助的已经样本数据的类别信息。尽管流形学习方法能够较好地处理非线性流形结构的语音特征数据,但是流形学习方法的性能容易受到其参数如邻域数的影响,而如何确定其最佳的邻域数,至今还缺乏理论指导,一般都是根据样本数据的多次试验结果来粗略地确定。因此,对于流形学习方法的使用,如何确定其最佳参数,还有待深入研究。
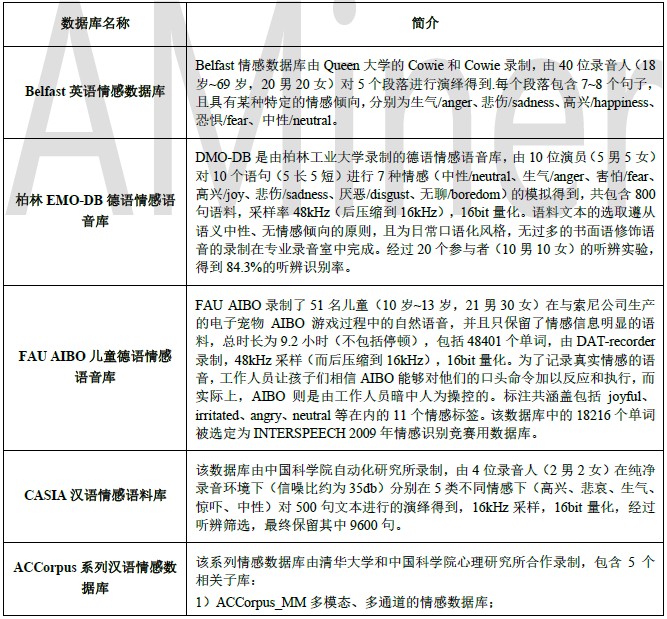
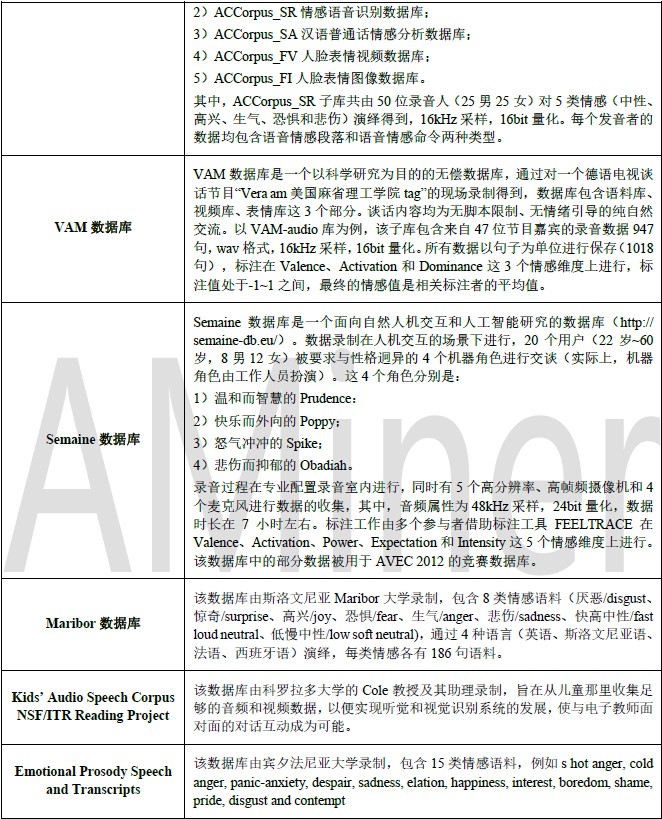
下表为常用语音情感数据库,供读者参考:
 最前沿的电子设计资讯
最前沿的电子设计资讯
