
在人工智能领域,谷歌一直是引领者和创新者。近日,这家科技巨头再次引起了业界的广泛关注,原因无他,正是其最新升级的大语言模型Gemini 1.5 Pro。此次升级不仅增强了模型的语言处理能力,更为其配备了一双“耳朵”——即音频理解能力,使得这款模型能够监听并分析上传的音频文件。
据EDN电子技术设计报道,谷歌在Google Cloud Next 2024大会上宣布了这一重大更新。Gemini 1.5 Pro作为谷歌功能最强大的生成式AI模型,此次升级进一步巩固了其在AI领域的领先地位。新版本的Gemini不仅可以将文本处理能力提升至新的高度,还能对音频内容进行深度分析和理解。

传统的语言模型多侧重于文本处理,对于音频内容往往束手无策。然而,在现实生活中,大量的信息是以音频形式存在的,如电话交谈、会议记录、讲座和广播等。这些信息蕴含着丰富的知识和价值,但由于技术的限制,一直难以被有效利用。Gemini 1.5 Pro的出现,正是为了解决这一问题。
通过深度学习技术,Gemini 1.5 Pro能够识别并解析音频中的语言结构,进而提取关键信息。无论是财报电话会议的录音,还是学术讲座的视频,只要上传到Gemini系统中,它都能迅速转化为可分析的文本内容,并为用户提供有价值的洞察。
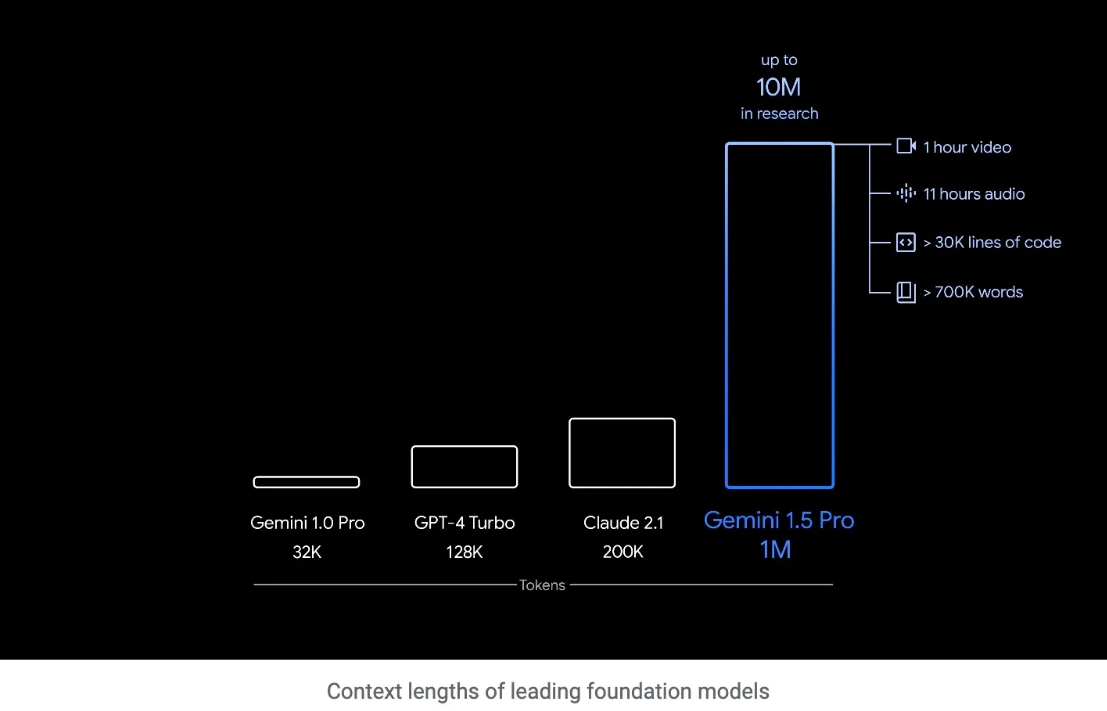
Gemini 1.5 Pro,被誉为Gemini系列中的“中量级”佼佼者,其卓越性能已经凌驾于规模庞大的Gemini Ultra之上。谷歌指出,Gemini 1.5 Pro具备理解复杂指令的能力,并且用户在使用时无需对模型进行特别调整,极为便捷。
但需注意,只有通过Vertex AI平台,用户才能充分体验Gemini 1.5 Pro的全部功能。目前,大众主要通过Gemini聊天机器人来与Gemini大语言模型进行交互。尽管Gemini Ultra为Gemini Advanced聊天机器人提供了坚实的支持,能够解析较长的指令,但在响应速度方面却不及Gemini 1.5 Pro迅捷。
除了Gemini 1.5 Pro的升级外,谷歌还对其他重要的人工智能模型进行了改进。特别值得一提的是文本转图像生成模型Imagen 2,它显著增强了Gemini的图像生成能力。通过新增的图像外延(Outpainting)和内填(Inpainting)功能,用户现在可以更加灵活地增加或删除图像中的元素。
为了保障Imagen模型生成图片的版权和来源可追踪性,谷歌为所有生成的图片加入了SynthID数字水印技术。这项创新技术通过几乎不可见的水印来明确标识图片的来源,并可通过专用工具进行检测。
Imagen模型的许多新特性,如图像外延和内填技术,已被其他文本转图像模型所采纳,例如Stability AI的Stable Cascade和Getty的Generative AI by iStock。此外,这些技术也广泛应用于消费电子产品中,例如三星Galaxy手机。
除了在图像生成方面的创新,谷歌还展示了一种将人工智能生成的回答与谷歌搜索结果相结合的方法,旨在为用户提供更加实时、准确的信息。然而,由于大语言模型生成的回答并非总是准确无误,有时可能会对用户造成误导。因此,谷歌对Gemini模型施加了一些限制,例如禁止回答与2024年美国大选相关的问题,以避免提供误导性的信息。
此前,Gemini模型在描述历史人物时曾出现不准确的情况,而受到了一些批评。谷歌正在不断努力改进,以确保模型的准确性和可靠性。
 最前沿的电子设计资讯
最前沿的电子设计资讯
