
1. 一体机 (All-in-One Machine)
2025年上半年最火的AI产品是什么?
绝对是DeepSeek一体机。
没有之一。
一体机,顾名思义,就是将计算、存储和部分互联功能集成在单个机箱内的智算机器。
一般配置 1到2颗通用型 CPU,核心数量适中,主要负责操作系统运行、任务调度以及一些非计算密集型的工作负载。
当然AI一体机中少不了GPU,通常配备 1到8块高性能 GPU。
这些 GPU 通过 PCIe 总线 直接连接到 CPU,实现高速数据传输。

实际部署在多 GPU 配置中,NVIDIA 的 NVLink 等专有互联技术可能用于 GPU 之间的高带宽、低延迟通信,这种互联虽然仅限于单机箱内部,实际部署中也比较少见。
所以一体机的数据交互,主要依靠 PCIe 总线 作为 CPU 与 GPU 之间以及 GPU 内部的主要互联方式。通常不涉及外部高速网络互联,因为其设计初衷是作为独立的计算工作站。
一体机的架构特点: 高度集成、部署简单、占用空间小。最重要就是便宜。
典型应用: 企业或者个人 AI 开发工作站、小型深度学习模型训练、边缘 AI 推理、图形渲染和设计等。例如DeepSeek一体机就是一种典型的产品形态。
2. 超节点 (Supernode)
一体机一般最多8张卡,算力有限。
因此更大规模的智算设备形态,超节点就应运而生。
超节点是比一体机更大规模的AI计算单元,它由多个计算节点(通常是服务器)通过高速网络互联而成,形成一个逻辑上的高性能计算模块。
一个超节点内部通常承载着强大的并行计算能力。
一个超节点可能由多台服务器组成,每台服务器通常配置2颗或更多 CPU,因此整个超节点可能拥有数十颗 CPU,提供强大的通用计算和任务管理能力。 超节点内部集成了 大量 GPU,数量远超一体机。每台服务器可能配置8块、16块甚至更多 GPU,因此一个超节点可能包含几十到上百块 GPU,为大规模并行计算提供核心算力。 而超节点的实物如下图所示,看起来就是一个平平无奇的机柜。  但是超节点的互联方式与一体机不同。 超节点内部GPU之间进行级联(scale up),沿用 PCIe 总线 。 但是最重要的是通过 NVLink(对于 NVIDIA GPU)把GPU连到了一起。 当然对于其GPU厂家,也有其他的(类似NVLINK)互联方式,实现 CPU 与 GPU 之间以及同一服务器内多 GPU 之间的高速互联。
但是超节点的互联方式与一体机不同。 超节点内部GPU之间进行级联(scale up),沿用 PCIe 总线 。 但是最重要的是通过 NVLink(对于 NVIDIA GPU)把GPU连到了一起。 当然对于其GPU厂家,也有其他的(类似NVLINK)互联方式,实现 CPU 与 GPU 之间以及同一服务器内多 GPU 之间的高速互联。 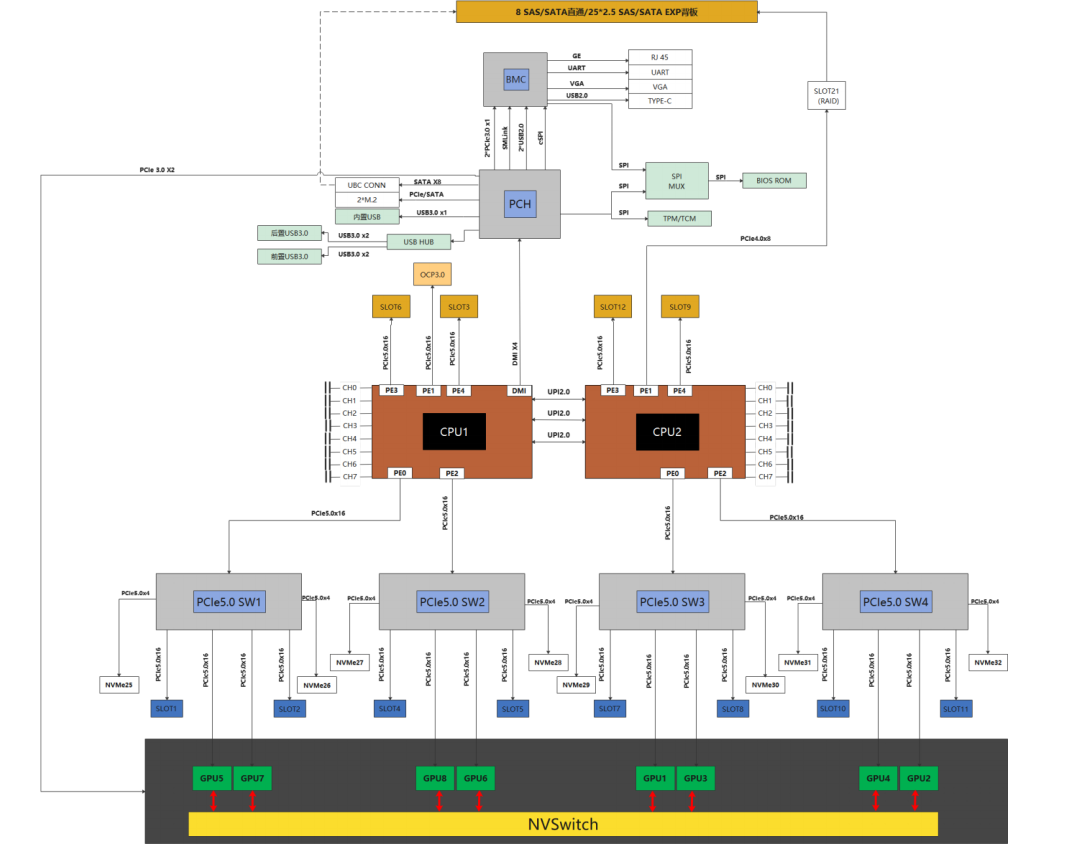 上图可以看到,超节点GPU和CPU之间,通过PCIe互联,而GPU之间通过NVSwitch实现NVLINK的互联,NVLINK的能够提供几个Tbps的互联带宽。这个比PCIe要快一个数量级。 而最近另一个比较有名的超节点的例子,就是华为的CLOUDMatrix384, 这个通过UB Switch实现了384个NPU和CPU的互联。
上图可以看到,超节点GPU和CPU之间,通过PCIe互联,而GPU之间通过NVSwitch实现NVLINK的互联,NVLINK的能够提供几个Tbps的互联带宽。这个比PCIe要快一个数量级。 而最近另一个比较有名的超节点的例子,就是华为的CLOUDMatrix384, 这个通过UB Switch实现了384个NPU和CPU的互联。 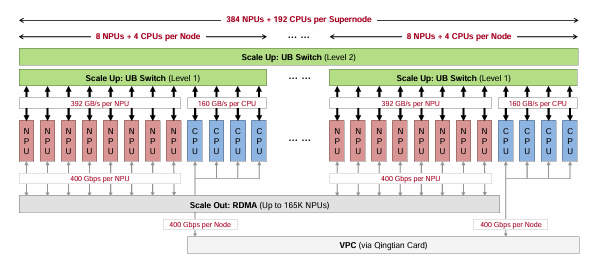 类似于NVLINK和UB Switch这些GPU之间scale up的互联协议是实现超节点各家的杀手锏。 同样从华为的例子来看,超节点的互联的带宽是很高的。 例如华为CLOUDMatrix384的一个GPU的UB接口达到了196GBX2的吞吐能力。
类似于NVLINK和UB Switch这些GPU之间scale up的互联协议是实现超节点各家的杀手锏。 同样从华为的例子来看,超节点的互联的带宽是很高的。 例如华为CLOUDMatrix384的一个GPU的UB接口达到了196GBX2的吞吐能力。 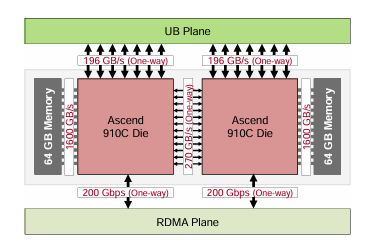
超节点典型应用: 很多超节点就是训推一体,既可以推理也可以训练,在训练方面,可以实现中等规模 AI 模型训练(如百亿参数级别)、复杂科学模拟、数据密集型分析、企业级高性能计算任务。
3. 智算集群 (Intelligent Computing Cluster)
当然,超节点可以实现几百张GPU的互联,如果是LLM大规模的训练的话,那么就会使用上万张GPU,那就变成万卡互联,甚至十万卡互联。
这就是智算集群,或者叫做万卡集群或者十万卡集群
这是目前最顶级的超大规模计算基础设施。
它由数千甚至上万个计算节点通过多层级、高带宽的互联网络组成,旨在提供无与伦比的计算能力,以支持超大规模 AI 模型训练、前沿科学研究和复杂工程仿真。
智算集群包含 海量的 CPU。集群中的每个计算节点都配置多颗高性能 CPU,整个集群的 CPU 数量可能达到数千甚至上万颗。CPU 主要负责集群管理、任务调度、数据预处理和一些通用计算任务。 万卡集群的核心是 海量的 GPU,数量可以从数千到上万块。这些 GPU 分布在数百甚至上千个计算节点中,形成一个庞大的并行计算资源池。 下图就是马斯克同志搞得十万卡集群的部分机柜。  从智算集群的架构来看,智算集群的互联是其最复杂也最关键的部分,旨在确保数万块 GPU 之间的高效通信。 网卡集群可以看做很多智算节点的互联: 在节点内部(专业术语scale up)依然采用 PCIe 总线 和 NVLink(对于 NVIDIA GPU)实现节点内部 GPU 与 CPU 的高速互联。 在节点之间(专业术语scale out):这是智算集群的精髓。它采用多层级、高带宽、低延迟的 RDMA 网络,并构建高度复杂的网络拓扑结构,例如多层 Fat-Tree、Dragonfly+、或定制的环形/网格拓扑。
从智算集群的架构来看,智算集群的互联是其最复杂也最关键的部分,旨在确保数万块 GPU 之间的高效通信。 网卡集群可以看做很多智算节点的互联: 在节点内部(专业术语scale up)依然采用 PCIe 总线 和 NVLink(对于 NVIDIA GPU)实现节点内部 GPU 与 CPU 的高速互联。 在节点之间(专业术语scale out):这是智算集群的精髓。它采用多层级、高带宽、低延迟的 RDMA 网络,并构建高度复杂的网络拓扑结构,例如多层 Fat-Tree、Dragonfly+、或定制的环形/网格拓扑。 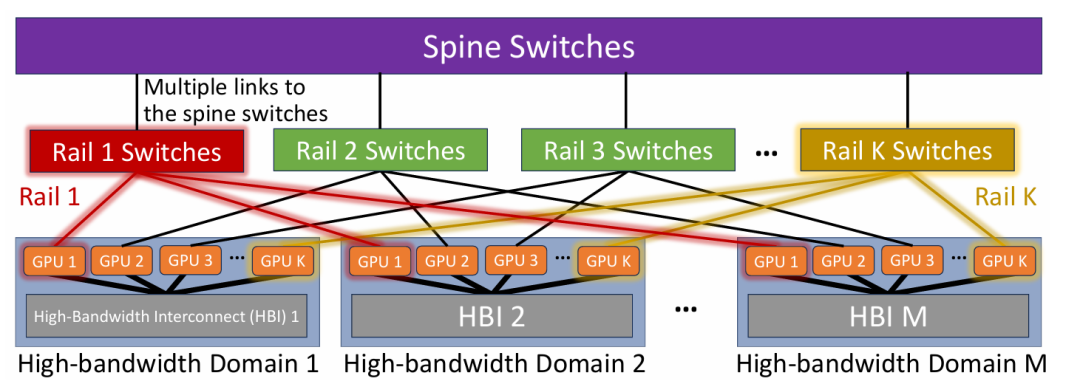 因此,万卡智算集群引入了 高速 RDMA (Remote Direct Memory Access) 网络,如 InfiniBand 或 RoCE (RDMA over Converged Ethernet),用于超节点内部不同服务器节点之间的高带宽、低延迟通信。 上图就是通过双层的交换机,连接不同的智算节点之间高速网卡(例如400G或者800G的网卡,一般是每块网卡对于一块高速GPU)。
因此,万卡智算集群引入了 高速 RDMA (Remote Direct Memory Access) 网络,如 InfiniBand 或 RoCE (RDMA over Converged Ethernet),用于超节点内部不同服务器节点之间的高带宽、低延迟通信。 上图就是通过双层的交换机,连接不同的智算节点之间高速网卡(例如400G或者800G的网卡,一般是每块网卡对于一块高速GPU)。 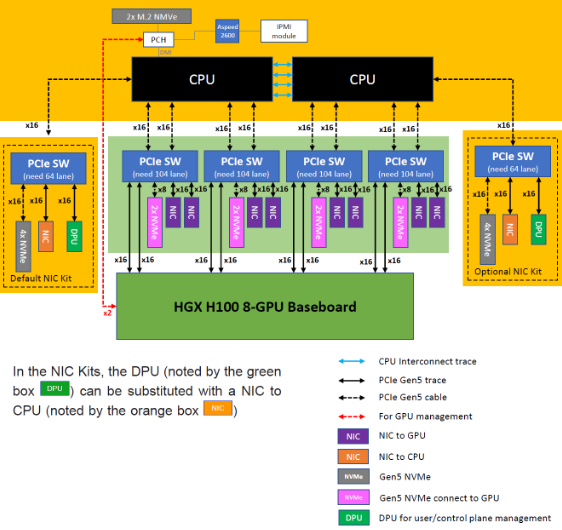 例如上图,每个GPU都要配合一张NIC(网卡(紫色所示)),从而在外部交换机上实现高速的互联。 这就是10万卡的集群的特色,不但是有PCIe的Switch,要有GPU之间的NVlink,还要有高速的(400G/800G)的RDMA网卡以及高速的51.2T/102.4T的交换机(400G*128/800G*128)。 这些智算服务器节点或者超节点通过网络连接起来,然后通过软硬件协同设计,并结合高性能通信库(如 NCCL),优化集群级的集体通信操作(All-reduce, All-gather等),确保数万块 GPU 能够像一个统一的计算单元一样协同工作。 这么大的集群,是很容易出问题的,一次训练需要几个月,但是集群无故障工作的时间也就是几天到几周。 因此庞大的规模要求集群网络具备强大的容错能力、智能的负载均衡机制和快速的故障恢复能力。
例如上图,每个GPU都要配合一张NIC(网卡(紫色所示)),从而在外部交换机上实现高速的互联。 这就是10万卡的集群的特色,不但是有PCIe的Switch,要有GPU之间的NVlink,还要有高速的(400G/800G)的RDMA网卡以及高速的51.2T/102.4T的交换机(400G*128/800G*128)。 这些智算服务器节点或者超节点通过网络连接起来,然后通过软硬件协同设计,并结合高性能通信库(如 NCCL),优化集群级的集体通信操作(All-reduce, All-gather等),确保数万块 GPU 能够像一个统一的计算单元一样协同工作。 这么大的集群,是很容易出问题的,一次训练需要几个月,但是集群无故障工作的时间也就是几天到几周。 因此庞大的规模要求集群网络具备强大的容错能力、智能的负载均衡机制和快速的故障恢复能力。
典型应用: 建造这种万卡或者十万卡的智算集群,其最主要研究就是AI训练,例如可以训练千亿甚至万亿参数级别的超大规模 AI 模型(如 GPT-4、Llama 3等),而也是最大的AI炼金炉。
 最前沿的电子设计资讯
最前沿的电子设计资讯

