随着人工智能(AI)和云技术的崛起,企业IT正经历着自互联网诞生以来最深刻的变革。这两股力量如同风口浪尖一般,共同重新定义了21世纪IT的格局。
云技术已经彻底改变了IT运营的"地点"。从过去的本地化到现在的云端,企业可以更加灵活地管理资源,提高效率。人工智能正极大地重塑着IT的"方式",开创了一个重新定义企业计算边界的时代。
● 数据的需求
随着数据在全球飞速增长,到2025年,全球数据创建将达到180 ZB。这种激增对性能提出了更高要求,数据需要更易于访问和使用,以支持现代应用程序和工作流程。这也催生了对IT基础设施的新需求。8swednc
人工智能的兴起不仅在超级计算中心和高性能计算领域迅速推动了基础设施需求,而且也在企业IT活动和用例中得到广泛应用。这为IT带来了前所未有的挑战,包括存储接口的使用等方面。在这个变革的时代,Linux社区正在推动数据路径性能的提升。特别是通过引入NFSv4.2,提高NFS协议的速度和效率,为数据密集型、分布式应用程序提供更好的支持。8swednc
● pNFS协议的演进
 8swednc
8swednc
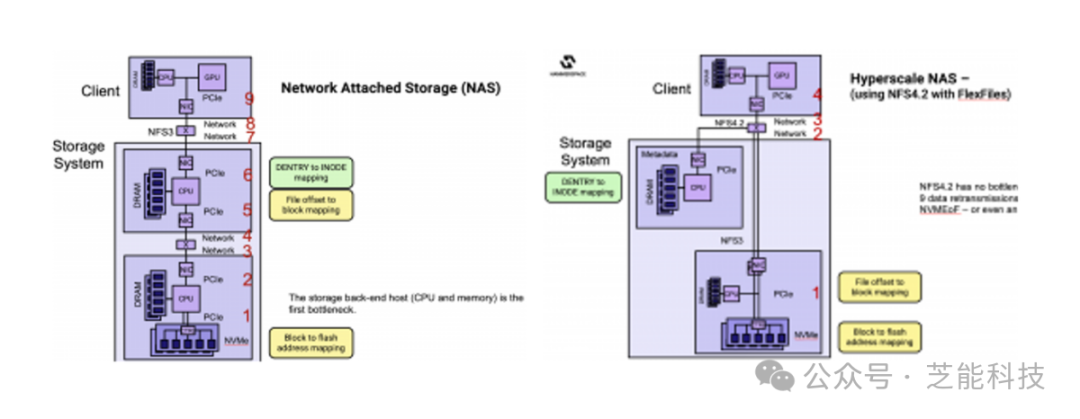
pNFS协议的引入解决了并行文件系统的问题,使NFS适应了大规模操作的现代用例。Hammerspace公司通过引入Flex Files对Linux社区做出了贡献,实现了实时文件移动性,提高了文件访问性能。Hammerspace公司在全球数据环境解决方案中采用pNFS和Flex Files,实现了超大规模NAS功能。与传统的横向扩展NAS相比,这种方法降低了数据路径的复杂性,提高了硬件性能。
随着以太网连接SSD(eSSD)的出现,NFS服务器可以直接嵌入到eSSD中,为数据重传、延迟等提供更好的性能。这种创新使得技术能够以更低的延迟、更少的数据重传和更低的功耗实现更高的可靠性和可维护性。当前IT结构的变革是未来可能性的先导。从互联网的早期到人工智能和云革命,每一次的进步都为下一次的飞跃创造了可能性。
在这个变革的时代,我们要适应变化,创造一个超越当今限制的未来,为企业、政府和学术界开辟新的视野。今天所拥抱的开放进步为明天的企业IT带来了无限的潜力。
为了实现高性能,GPU需要在计算过程中能够无缝地访问数据。目前,GPU直接存储等技术正在推动通过高带宽链接对大量存储进行访问。为了在GPU和存储阵列之间建立高效的通信,必须设置多个并行通道。
这其中,选择合适的通信方式对于保证网络通道的饱和度至关重要。传统的NFSv3服务器在处理这样的负载时显得力不从心,因为它的设计是基于单服务器、多客户端模型的。为了实现链路的完全饱和并保持GPU的高负荷运转,必须建立一个包含多个I/O路径的框架,以推动存储和计算之间的并发I/O。并行文件系统的出现旨在将数据划分为多个部分并将其存储在多个服务器上,以实现并发访问。这种文件系统能够独特地索引数据的各个区域,从而实现同时访问。通过协调多个I/O路径的使用,大大提高了I/O性能。
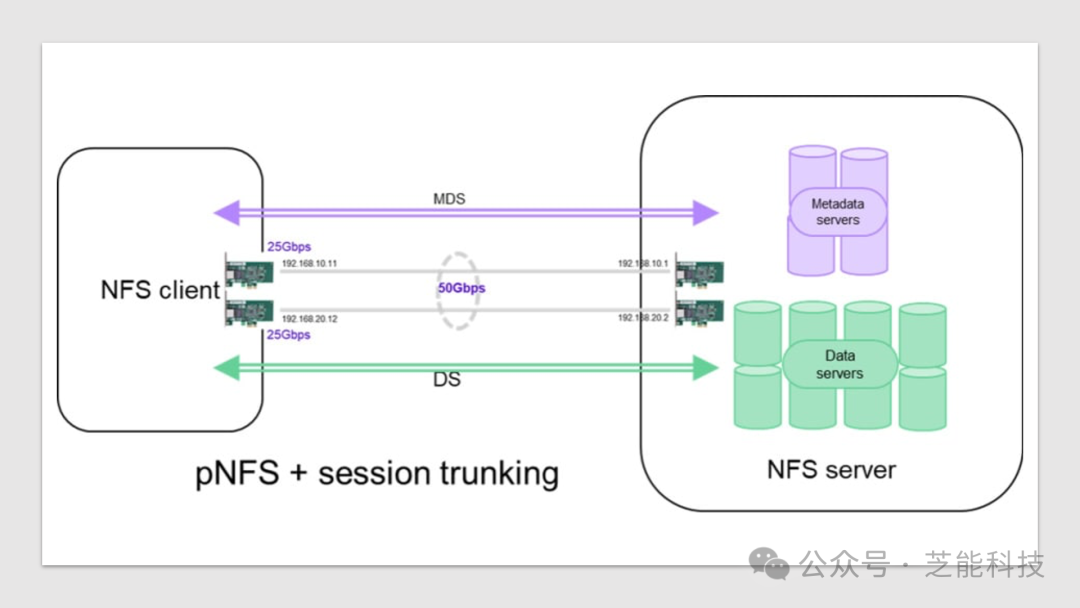
NFS 4.1版本是对一些NFS高速访问限制的重大重新设计,旨在提升性能。并行NFS(pNFS)是其中的一项关键功能,支持真正的横向扩展,使数据可以分布在多个服务器上,客户端可以通过多个路径直接访问。pNFS的另一个显著特征是,它使客户端能够使用文件布局驱动程序与服务器进行通信,从而隔离了元数据和数据的流量,使其可以由集群内的不同服务器独立提供服务。在NFSv4.1中引入的会话中继功能解决了网络带宽最大化的问题。通过在同一会话中关联多个连接,会话中继实现了将所有可用接口上的吞吐量聚合到数据服务器的目的,从而提高了网络带宽的利用率。这种聚合通过在同一会话中动态建立连接来完成,每个连接具有可能不同的源和目标网络地址。
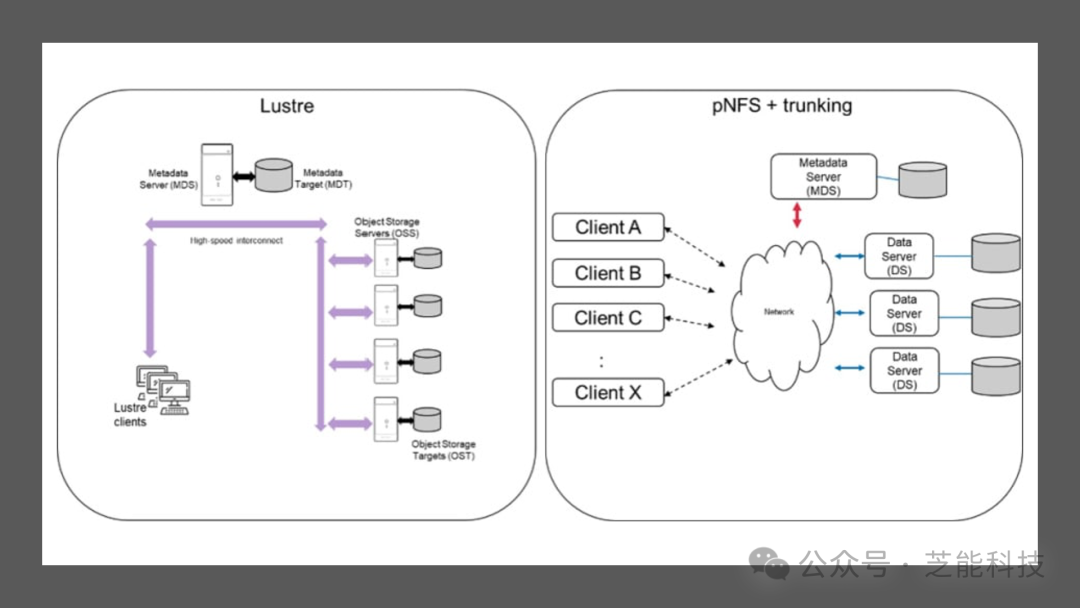
将多路径功能与pNFS相结合,创造了一个集中通道,可以同时承载文件系统的元数据或读/写流量,或两者兼而有之。这种架构与其他并行文件系统相似,但避免了高昂的设置和维护成本。整合了Lustre和pNFS的中继流程图清晰地展示了它们之间的相似性。NetApp ONTAP通过支持FlexGroup、基于RDMA的NFS、pNFS和会话中继等技术,为AI/ML工作负载提供了强大的支持。
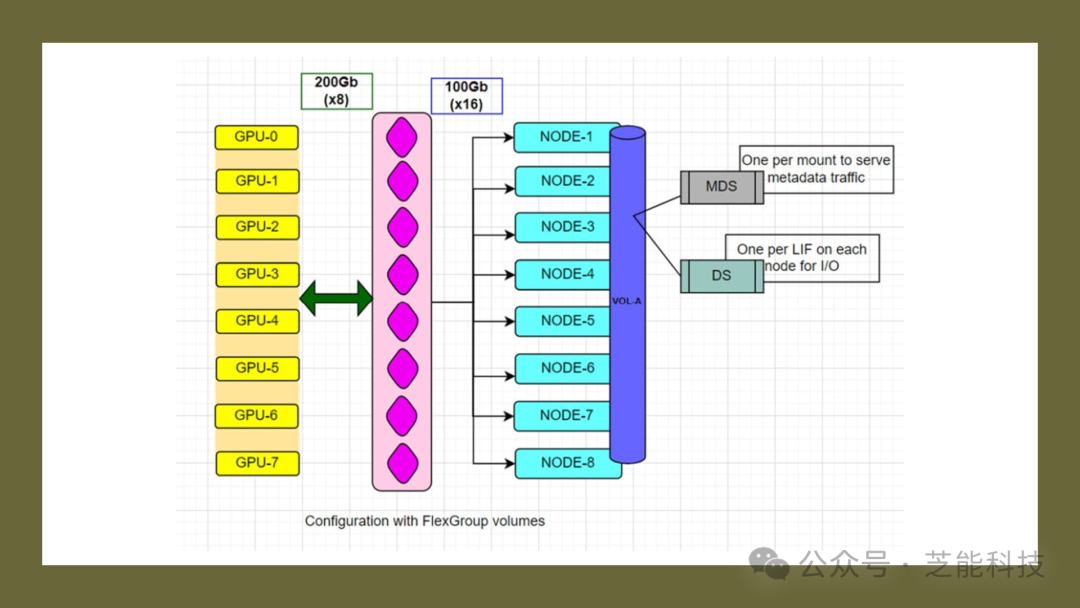
FlexGroup卷的能力使数据在整个集群中均匀分布,消除了集群中的性能热点。ONTAP还通过支持NFS over RDMA传输规范,消除了内存复制的低效问题,提高了数据传输效率。
ONTAP的FlexGroup卷为处理不断增长的AI/ML数据集提供了灵活性。通过支持NFS over RDMA传输规范,ONTAP通过消除内存复制的低效性,直接从主机系统内存向服务器传输数据,有效地减轻了CPU的负担。此外,ONTAP的pNFS和RDMA挂载的会话中继进一步提高了网络带宽的利用率,帮助AI/ML工作负载适应不断增加的用例。支持GPU直接存储的NVIDIA DGX A100系统连接到NetApp AFF A800集群,吞吐量达到了线路速率的86%。这种配置下,每个节点仍有扩展空间,表明ONTAP可以轻松支持AI/ML工作负载的不断增加。
时代确实在快速的变化和发展,NFSv4.1的革新还是带来很大的变化。
责编:Ricardo

 最前沿的电子设计资讯
最前沿的电子设计资讯

