
这已经不是技术问题,是生存问题了。
当时的大佬们(CPU、GPU)虽然能打,但又贵又耗电,性价比太低。
谷歌寻思着,这不行啊,不能总靠友商,得自己造“核武器”。
于是,一个“军令状”立下了:搞一个比同期GPU性价比高10倍的玩意儿出来!
TPU(Tensor Processing Unit,张量处理单元)的故事,就这么拉开了序幕。

第一章:V1出世,一个“偏科”的天才
谷歌的工程师们没有重新发明轮子,而是从故纸堆里翻出了一本上古秘籍——70年代末提出的“脉动阵列”(Systolic Array)。
这玩意儿听着玄乎,其实原理很“带感”。
你想象一下,把数据像“泵”一样,有节奏地“泵”进一个由成千上万个计算小单元组成的网格里。
数据在这个网格里流动,每流过一个单元,就被计算一次,结果直接传给下一个,全程无缝衔接,像心跳一样规律
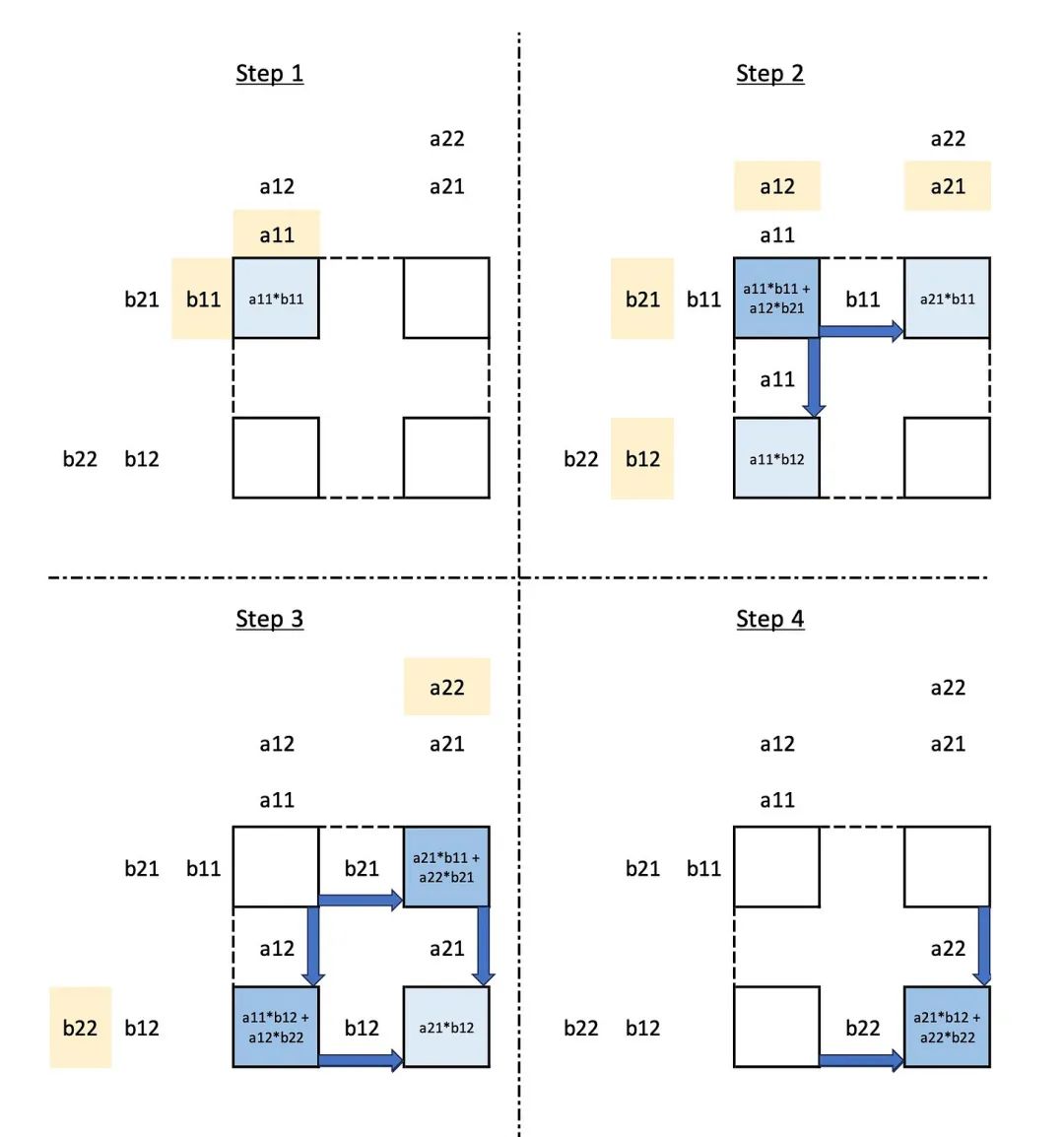
这套操作最大的好处是啥?
省事儿!
数据不用频繁地在内存和计算单元之间来回跑,极大减少了能量和时间开销。
TPU v1就把这个上古神功练到了极致。
它的核心是一个巨大的256x256矩阵乘法器(MXU),里面塞了65536个8位计算单元
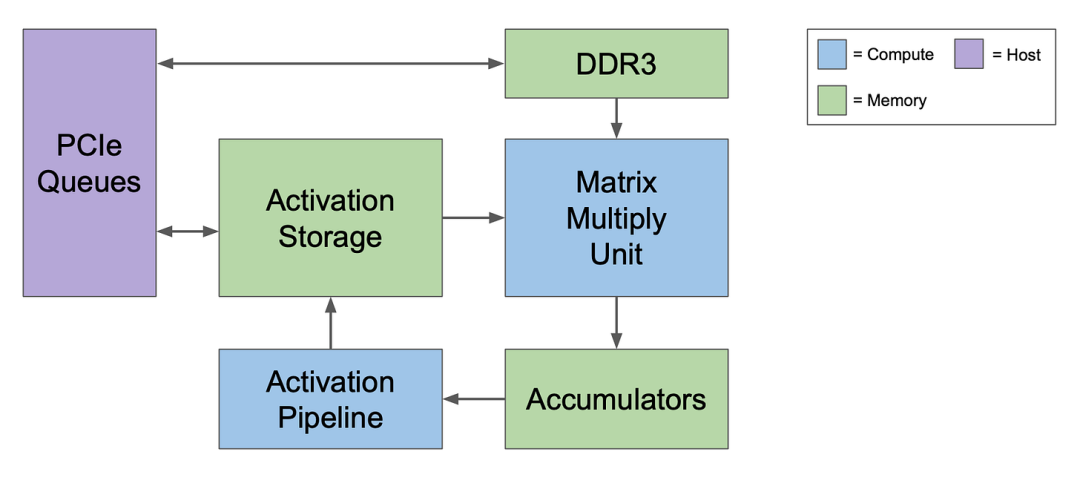
为了把性能压榨到极限,它做了一个极其大胆的决定:
砍掉所有花里胡哨的功能!
什么缓存、分支预测、乱序执行,统统不要
它只干一件事,就是做矩阵乘法,而且是用8位整数(INT8)去做
这波“断舍离”的回报是惊人的:
在谷歌内部的真实业务(比如搜索排名)上,TPU v1比当时的CPU、GPU快了15到30倍 。
能效比更是后者的30到80倍
不过,它不是一个独立的“大哥”,而是个超级能打的“马仔” 。
CPU大哥发个指令,比如“算个卷积”,TPU v1就埋头吭哧吭哧地把活儿干完,又快又稳。
后来,在举世闻名的AlphaGo大战李世石中,TPU v1就是幕后英雄之一,主要负责帮AlphaGo进行海量的自我对弈训练。
这一战,让TPU彻底出圈,成了AI江湖里一个响当当的名号。
第二章:V2转身,从“单挑王”到“超级战队”
v1虽然猛,但它是个“偏科生”,只能搞推理(inference),不能搞训练(training)。
谷歌很快意识到,真正的瓶颈在于训练模型,那计算量比推理大好几个数量级
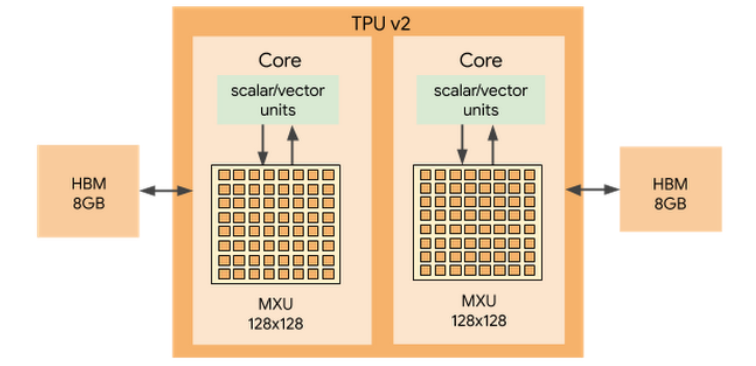
于是,TPU v2的设计目标发生了180度大转弯:不造一颗更快的芯片,而是要造一台“AI超级计算机”。
为了这个宏伟目标,v2进行了三大“魔改”:
1:训练模型需要高精度,但32位浮点(FP32)太占地方。谷歌大脑的天才们就发明了一种叫bfloat16的16位浮点格式
这玩意儿堪称神来之笔:它保留了FP32的动态范围(不容易溢出),但砍了一半的精度位(反正神经网络对精度没那么敏感) 。
好处是,硬件开销小了一大圈,性能直接翻倍,还不用像其他16位浮点那样搞一堆复杂的防呆设计。
堪称硬件和算法“协同设计”的典范。
2:换上了“消防栓”:
v1的内存带宽就像个小水管,完全喂不饱计算单元。
v2直接换装了高带宽内存(HBM),带宽暴涨17倍,从34 GB/s飙到600 GB/s 。
从此,计算核心再也不怕“饿肚子”了。
3:组建了TPU Pod:
谷歌用一种叫“2D环形互连”(ICI)的定制高速网络,把256颗TPU v2芯片直接连在了一起,组成了一个“TPU Pod” 。
在这个Pod里,所有芯片可以像一个巨型加速器一样协同作战,总算力高达11.5 PetaFLOPs
这标志着谷歌的思路彻底变了:
不再是设计芯片,而是在设计一台领域专用的超级计算机。
第三章:V3猛击,力大砖飞与“水冷散热”
它不是革命,而是一次简单粗暴性能升级。
策略就一个字:加倍!
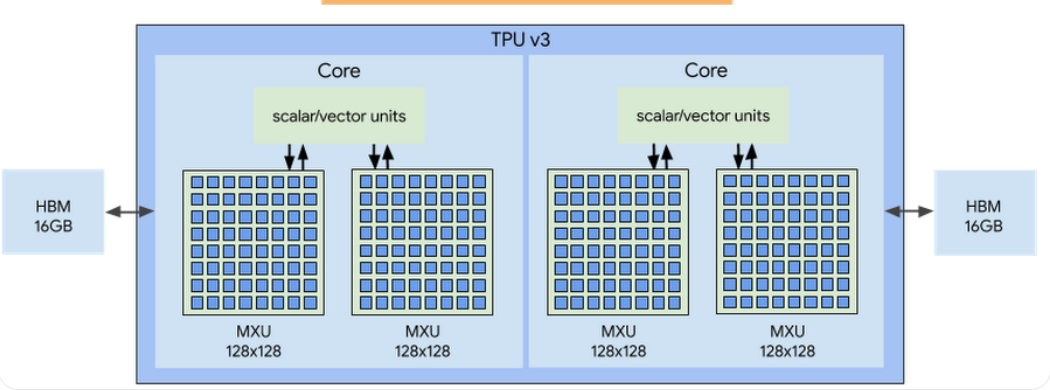
计算单元加倍,单芯性能翻倍到123 TFLOPS
内存加倍到32GB,带宽提升到900 GB/s
Pod规模翻了四倍,达到1024颗芯片,总算力突破100 PetaFLOPs 。
但是,性能加倍的代价是功耗也跟着飙。
单颗v3芯片的功耗高达450W
怎么办?
上水冷!
这是谷歌第一次在数据中心大规模引入液体冷却。

这事儿说明了一个深刻的道理:在超算的世界里,性能、互连、密度和散热是“生死兄弟”,一荣俱荣,一损俱损。
想把性能往死里堆,就得接受“泡澡”的命运。
第四章:V4革命,给超算装上“任意门”
如果说v3是力大砖飞,
那v4又加入新的互联手段。
它的核心革命在于互联技术——光学电路交换(OCS)

以前的互连网络,不管是v2还是v3,都是焊死的“高速公路”,拓扑结构是固定的。
但v4的OCS,像给整个超算系统装上了“任意门”。
它用微型镜面阵列来引导光路,可以在毫秒之间,动态地改变任意两个TPU集群之间的连接
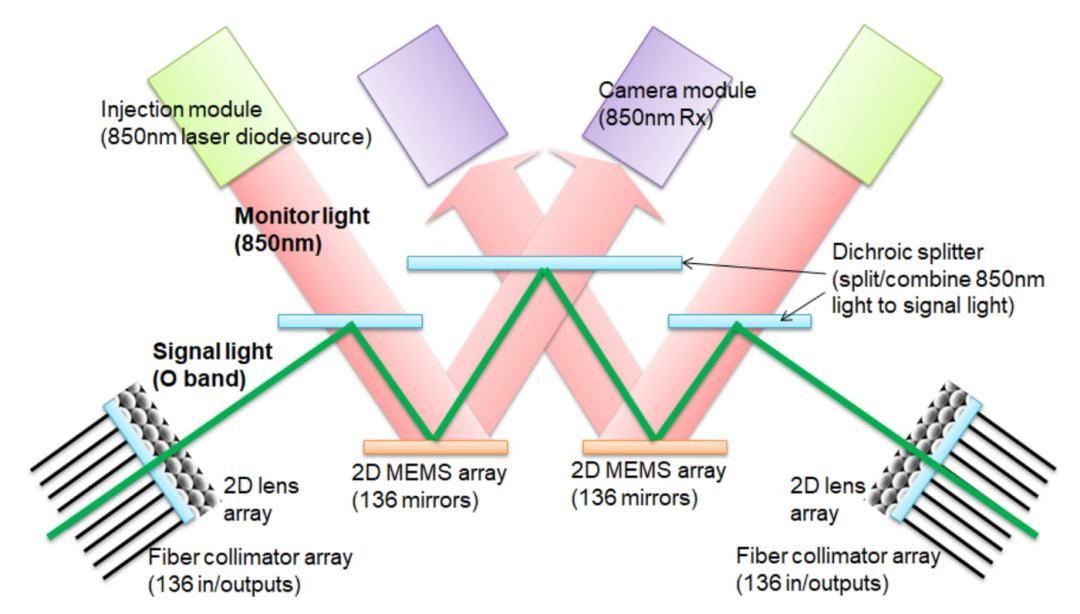
这带来了几个逆天的好处:
故障自动绕行:4096颗芯片组成的系统,训练个大模型动辄几周,中间坏掉一两个芯片太正常了。有了OCS,系统可以直接“绕开”故障节点,保证训练任务不中断。这可用性,直接拉满
拓扑随心变:不同的AI算法,喜欢的“阵型”(网络拓扑)不一样。
OCS可以根据任务需求,动态组合出最适合的“切片”形状,比如“雪茄型”或者“魔方型”,把通信效率提到最高
这已经不是简单的升级了,这是把物理网络变成了软件定义的资源。
谷歌的PaLM大模型,就是靠着6144颗v4芯片,以接近60%的硬件利用率训练出来的,OCS功不可没
此外,v4芯片内部还搞起了“异构架构”,
塞进了一个叫SparseCore的专用单元
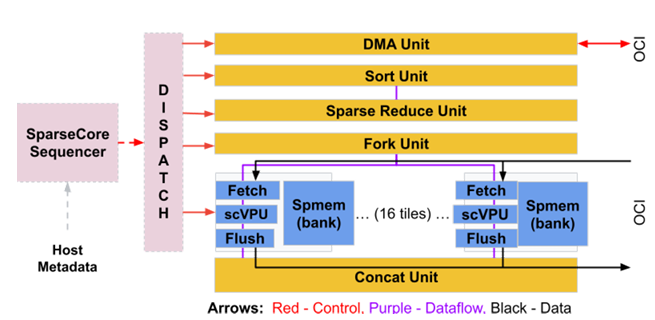
这是类似GPU的SIMD的组件。
这玩意儿专门对付推荐模型里那种不规则、老大难的嵌入查找操作。
虽然只占了5%的芯片面积,却带来了不小的性能提升
TPU也开始走向异构了。
第五章:V5/V6分化,卷王与经济适用男
到了v5时代,谷歌也学精了,搞起了产品线分化
'p'系列 (Performance):比如v5p,这是“性能卷王”,不计成本,就是要干最猛的活,训练Gemini这种级别的巨无霸模型。单芯算力459 TFLOPS,95GB HBM内存,能组8960颗芯片的超级Pod 。
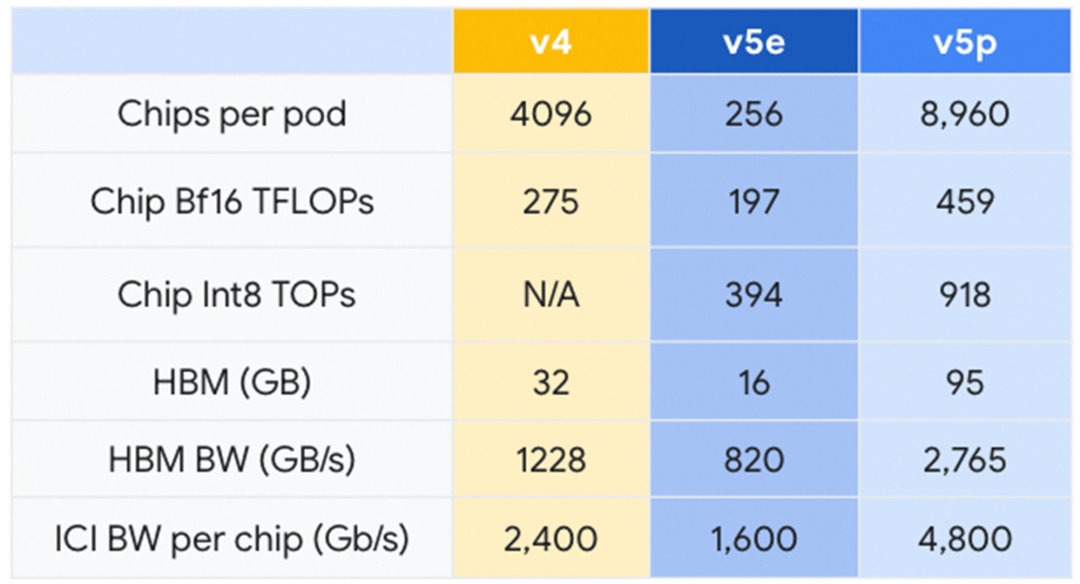
'e'系列 (Efficiency):比如v5e和最新的Trillium (v6e),这是“经济适用男”,主打性价比和能效比 。v5e的性价比就比v4高了2.5倍

而最新的Trillium (v6e)更是重量级,单芯算力比v5e猛增4.7倍,能效也提升了67%
这种分化说明AI硬件市场已经熟了,不再是“一招鲜吃遍天”,而是要针对不同客户提供不同价位的最优解。
谷歌甚至还预告了下一代专门为“推理时代”设计的Ironwood (TPU v7),内存和带宽参数更是夸张到没朋友
看来,专业化的道路要一条道走到黑了。
那么对于大模型(LLM)的训练,TPU的能效怎么样?
LLM 的核心是 Transformer 架构,其计算密集的部分就是大规模的矩阵乘法。TPU 的脉动阵列(MXU)天生就是为了高效执行这类运算而设计的 。
谷歌明确表示,TPU v4 和 v5e 都参与了 Gemini 的训练,而性能更强的 TPU v5p 的发布,正是为了支持像 Gemini 这样的前沿模型而量身定制的 。
尾声:《十年》
从一个为了解决生存危机的“救火队员”,到如今驱动世界顶级AI模型的Exa级超级计算机。
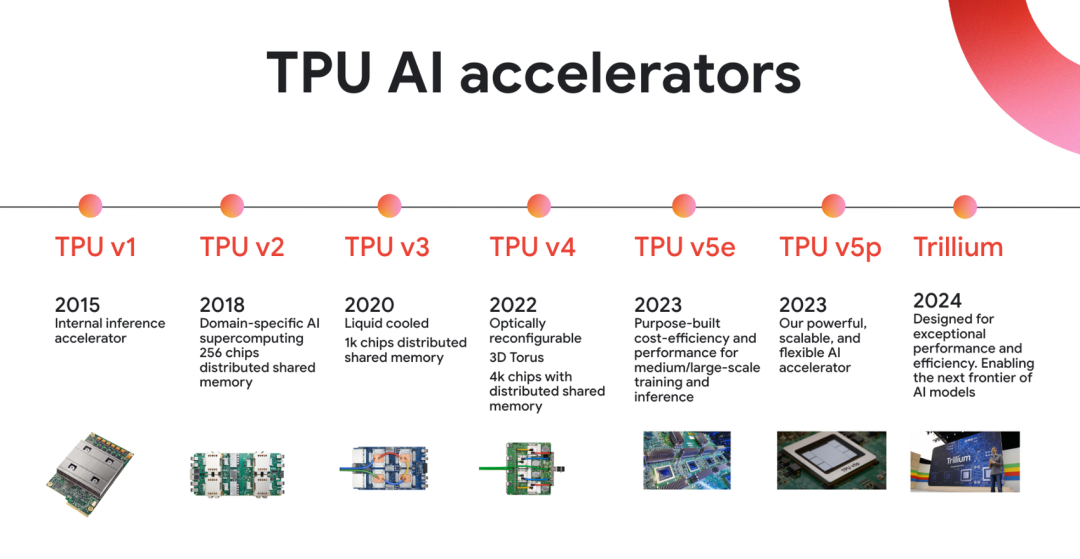
TPU的十年,就是一部AI需求与硬件创新相互追逐、相互成就的史诗。
 最前沿的电子设计资讯
最前沿的电子设计资讯

