aRLednc
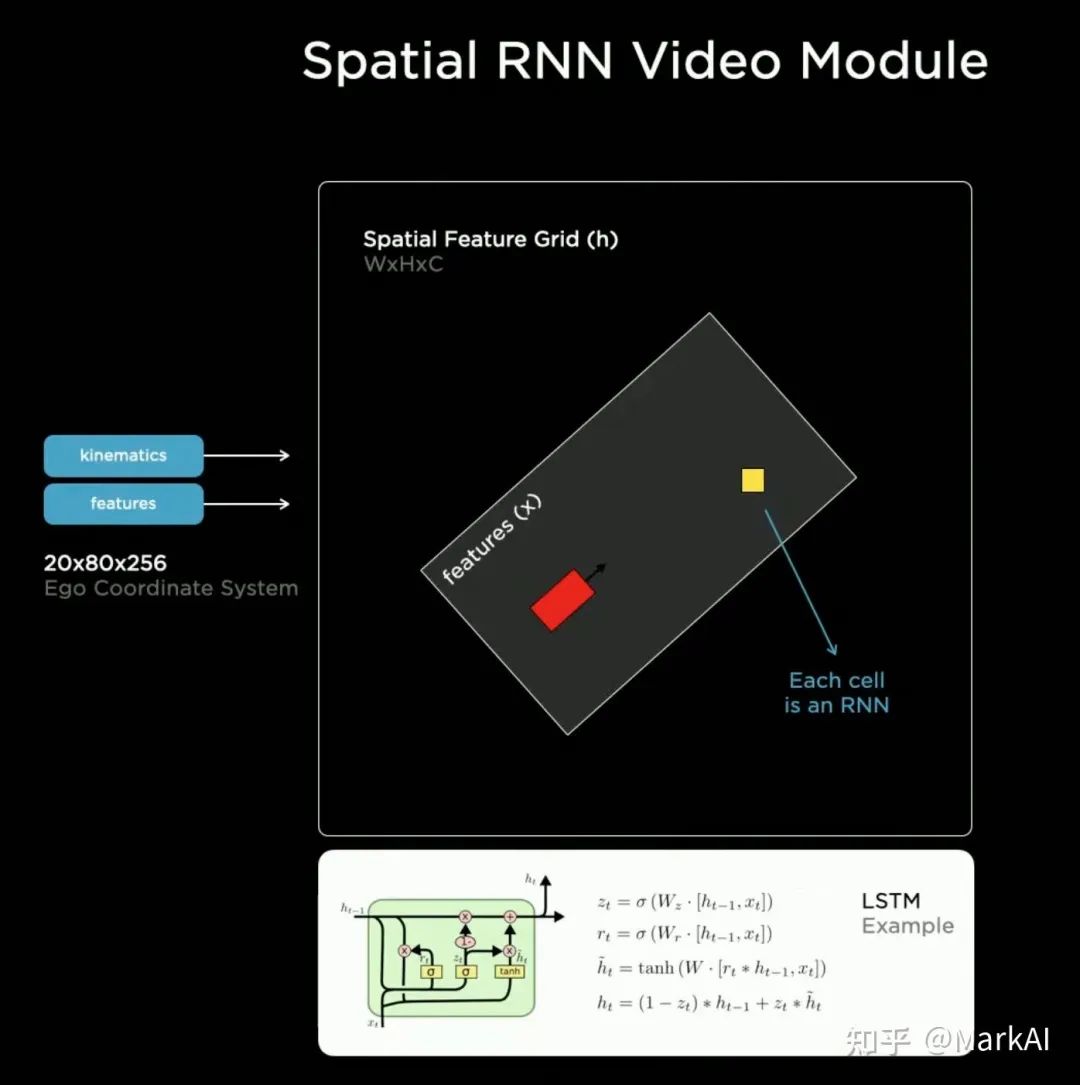
前面提到的特征队列只是用来组织时序信息,接下来介绍的视频模块要用来整合这些时序信息。Tesla团队选择了使用RNN结构来作为视频模块,并命名为空间RNN模块(Spatial RNN Module)。aRLednc






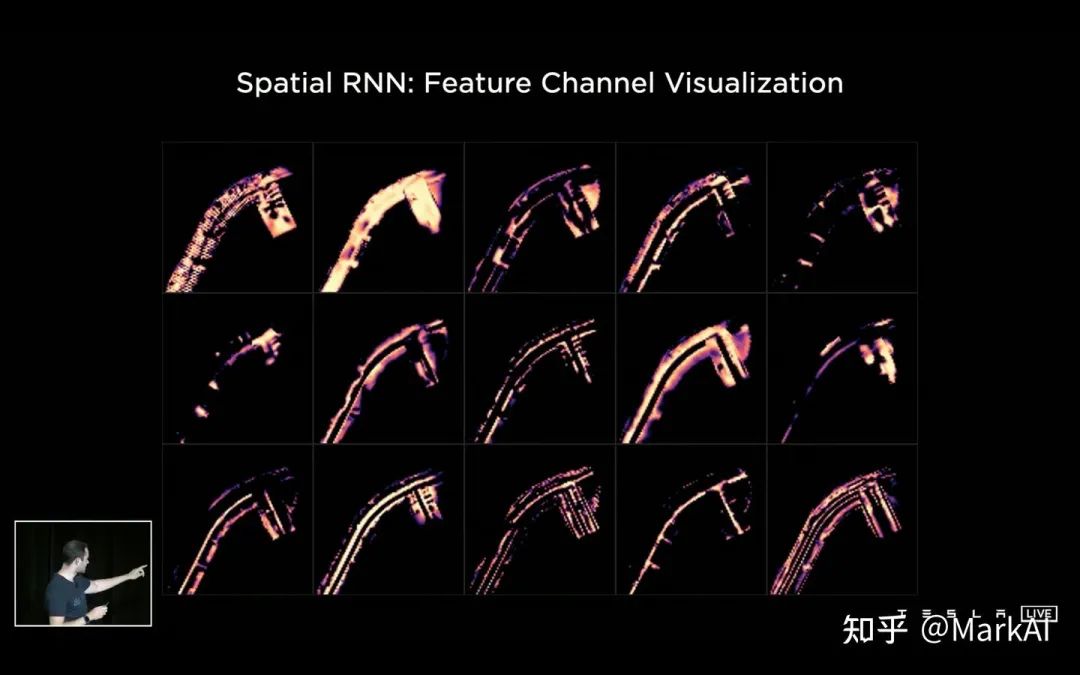
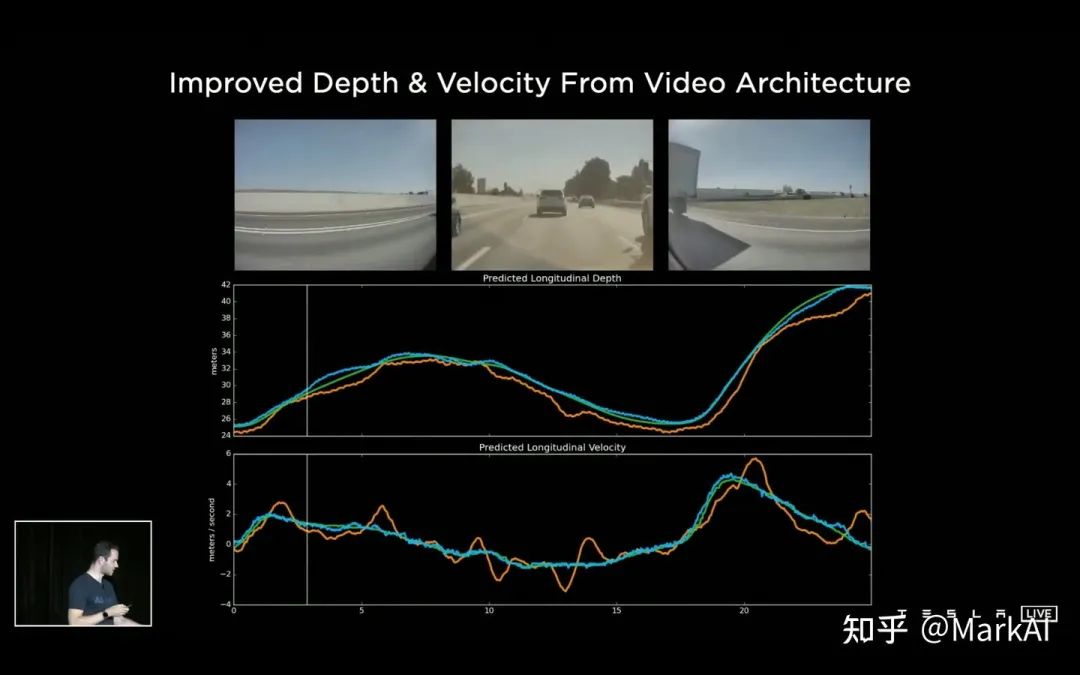
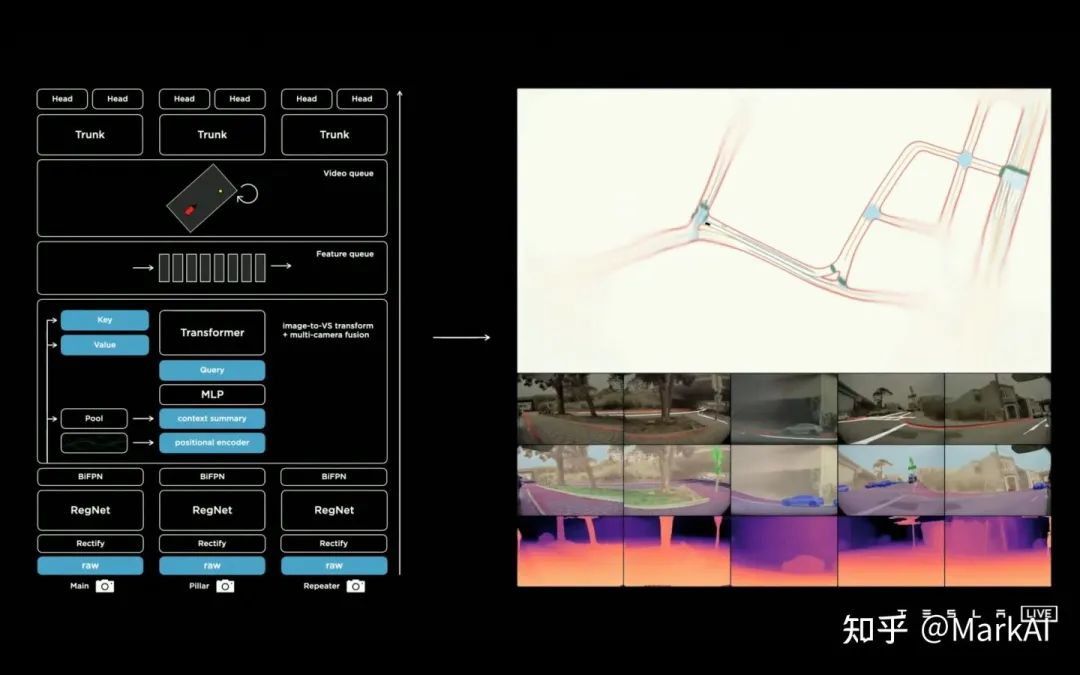

 最前沿的电子设计资讯
最前沿的电子设计资讯

